La base nationale des décès est un ovni statistique : c’est une des rares bases open data France entière qui décrive des personnes avec leurs nom et prénoms en clair. Aussi surprenant que cela puisse paraitre, les fichiers de l’Insee relatifs aux personnes décédées ne constituent pas des données à caractère personnel. Ils ne relèvent pas du secret de la vie privée, ce dernier ne protégeant que les individus en vie. La loi Informatique et Libertés (loi n° 78-17 du 6 janvier 1978) s’applique uniquement aux données concernant des personnes vivantes.
La base des décès comprend aujourd’hui près de 29 millions de décès survenus après 1970. C’est l’année à partir de laquelle les communes ont systématiquement transmis les mentions de décès à un répertoire national géré par l’Insee.
L’Insee n’en ouvre la diffusion à tous qu’en 2019, tenu de se plier à un arrêt de la Commission d’accès aux documents administratifs (Cada), saisie par un usager à qui le directeur de l’Insee avait d’abord répondu niet. Auparavant, seuls quelques généalogistes ou rediffuseurs pouvaient l’exploiter sous convention, par exemple en proposant un moteur de recherche sur internet.
La base des décès comprend des informations très simples : nom, prénoms, sexe, date et lieu de naissance et de décès, n° d’acte. C’est un fichier purement administratif, issu de l’activité d’enregistrement des communes. Il a de multiples qualités – sa simplicité et son exhaustivité pour les années récentes -, mais aussi quelques défauts – des doublons, des manques et des imprécisions.
Plusieurs formats de mise à disposition : txt, csv et parquet
Pour celles et ceux qui veulent explorer ces données sans limite, avec leurs propres outils, la base est accessible sous 3 formats différents, le 3e simplifiant radicalement la donne :
- 62 fichiers txt diffusés par l’Insee sur data.gouv.fr, annuels et mensuels pour l’année en cours, avec chaque enregistrement brut à décoder selon un dictionnaire par position ;
- 17 fichiers csv diffusés par l’Insee sur insee.fr, mensuels, annuels et décennaux, déjà délimités (sauf curieusement nom et prénoms) ;
- Un fichier national unique au format parquet (600 Mo), agrégé mensuellement par l’équipe de data.gouv.fr, qui a pris là une bien belle initiative.
Je récupère ce fichier parquet national et, évidemment, je tape d’abord mon nom (branche paternelle donc, puisque la base renseigne le nom de naissance), dans une requête SQL basique (DuckDB).
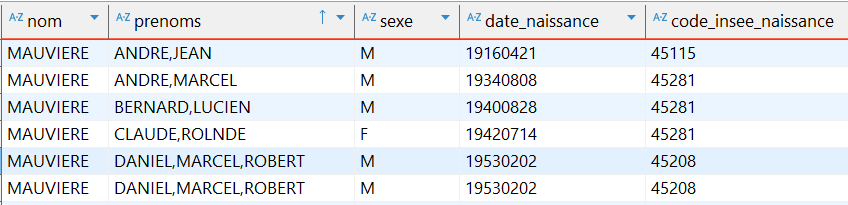
Je connais bon nombre de ces personnes, dont le décès m’est contemporain. La plupart sont nées dans un tout petit cercle géographique. Mais une répétition m’intrigue, Daniel apparait deux fois, et les deux lignes qui le concernent sont strictement identiques.
Voilà qui jette un premier doute sur la qualité de cette base : elle comporte à l’évidence des doublons. Il s’agira plus tard d’en évaluer la proportion, et voir comment les éliminer.
Des doublons, mais aussi des décès manquants, sur des périodes bien précises
Une façon rapide d’évaluer la qualité globale des données consiste à dessiner les évolutions dans le temps, par exemple celle des décès chaque année.
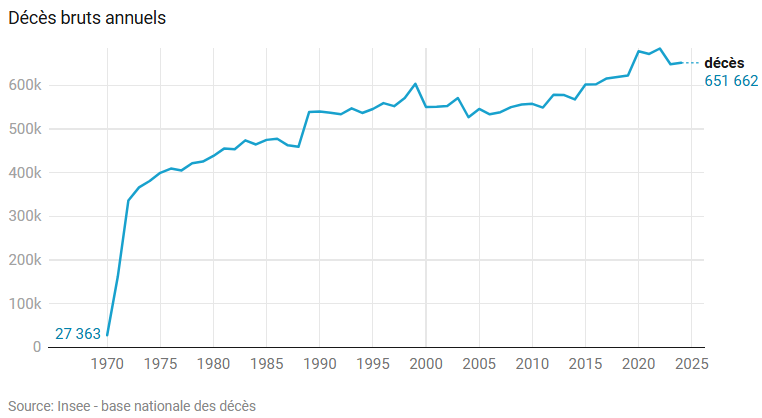
Il semble que les communes aient eu besoin d’un petit délai pour bien remonter toutes leurs déclarations de décès vers le nouveau fichier centralisé.
Resserrons à partir de 1972, et détaillons la série par mois. Deux anomalies sautent alors aux yeux.
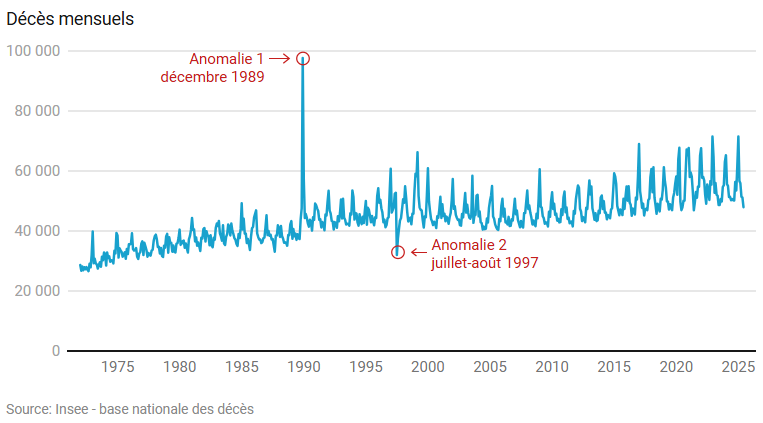
Si décembre est généralement le mois le plus meurtrier, passer de 50 000 à près de 100 000 de novembre à décembre 1989, cela fait beaucoup. Il devient urgent de regarder de plus près la présence de doublons.
C’est assez simple en SQL avec DuckDB :

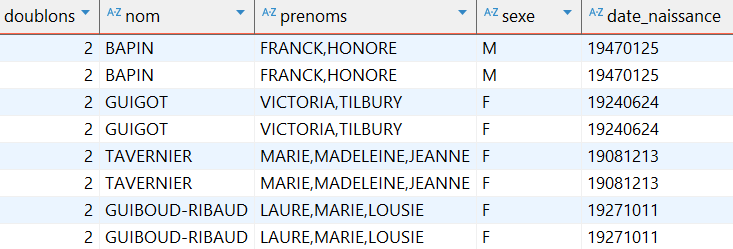
Il apparait que 121 000 lignes sont des répétitions intégrales : des enregistrements répétés jusqu’à 20 fois pour la même personne, et même 40 fois pour une Marie Cabre, décédée en 1999 !
Pour nettoyer davantage, je choisis quelques critères a priori suffisants pour définir l’unicité d’un dossier décès. J’ai constaté que certains doublons ne différaient que par la transcription du n° d’acte, par exemple 19 versus 0000019.
Cette requête produit directement un jeu de données dédoublonné :
28 428 608 dans ce jeu nettoyé contre 28 649 414 dans la base initiale, cela fait 221 000 doublons éliminés (dont une bonne moitié de doublons intégraux), soit 0,8 % de l’ensemble. Cela parait peu, mais voyons comment ces doublons se répartissent dans le temps, en comparant la base initiale et ce nouveau jeu de données nettoyé.
En bleu, les décès corrigés, sans doublons ; en gris, la différence avant/après le filtrage, c’est-à-dire le nombre de doublons.
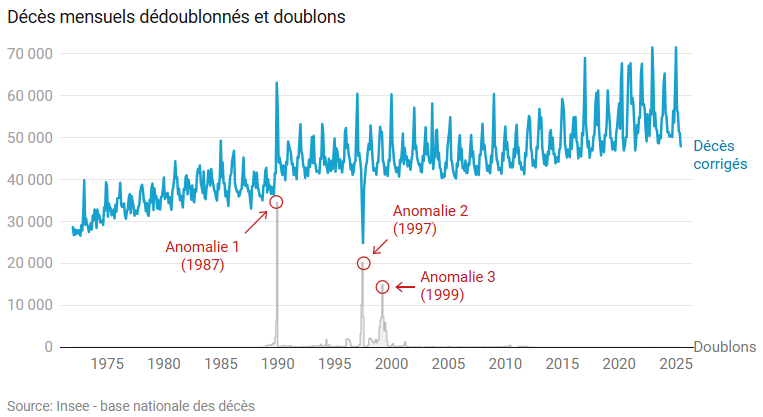
Surprise : les doublons sont très concentrés sur quelques périodes mensuelles. Notre anomalie 1, la surmortalité de décembre 1989, n’en est potentiellement plus une après correction. Et en effet, un Insee Premiere datant de mes débuts à l’Insee (admirez le logo de l’époque, la fameuse « nouille »), l’explique « L’augmentation d’environ 5 000 décès par rapport à l’année précédente est en particulier due à une importante épidémie de grippe survenue à la fin de l’année ». Mais rien ne permet de comprendre que cette surchauffe épidémique ait aussi, à ce point, cancérisé les données de décembre.
Plus étonnant encore, l’anomalie 2, le creux de l’été 1997, se retrouve amplifiée après nettoyage ! Pour juillet et août 1997, il manque clairement plusieurs milliers de décès dans la base. J’ai pu lire dans le fil de discussion de la fiche data.gouv.fr que ces deux anomalies avaient déjà été signalées à l’Insee (lequel se montre réticent à corriger ses vieux fichiers – certes il y a toujours mieux à faire, mais tout de même !).
Enfin, une troisième anomalie – pic de doublons – apparait autour de mars 1999.
La base des décès a mis 20 ans à atteindre l’exhaustivité
Après cet opportun dédoublonnage, et pour mieux apprécier l’exhaustivité de la base, rapprochons là des statistiques annuelles de décès, qui bénéficient de retraitements plus fins. Comme il est facile de filtrer la base nationale des décès sur la seule France métropolitaine, je retiens ce champ pour la comparaison.
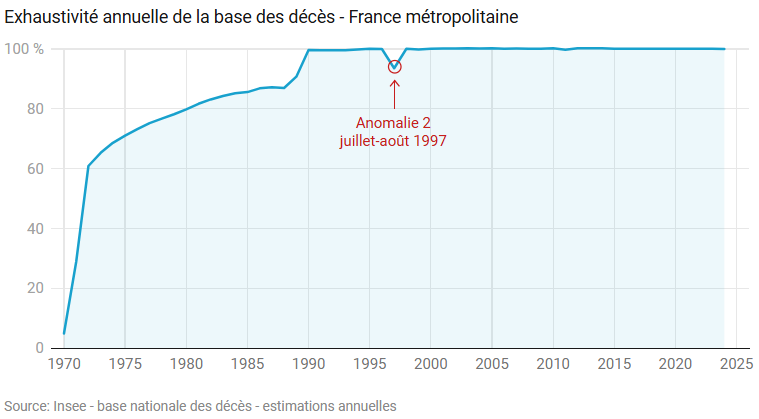
Il devient ainsi clair qu’il aura fallu vingt ans à la base nationale des décès pour atteindre l’exhaustivité, à partir de 1990, à l’exception de 1997 où, on l’avait pressenti et cela se confirme, des données estivales manquent – de l’ordre de 30 000 décès évaporés, dont j’aimerais connaitre l’explication…
Le codage des dates et des lieux nous rappelle l’histoire coloniale de la France
Tout d’abord, prenons conscience que les personnes de la base, décédées après 1970, sont nées, pour l’essentiel (83 %), avant la fin de la Seconde Guerre mondiale. Et donc avant la décolonisation en Afrique ou en Asie du Sud-Est.
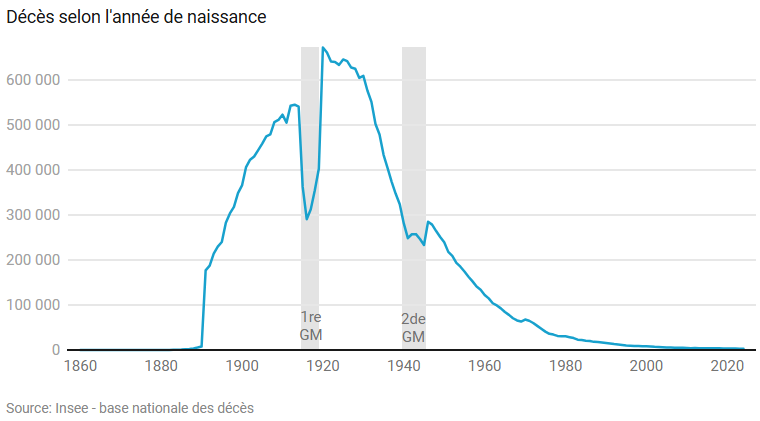
La diversité des lieux de naissance, la plupart des communes en France actuelle par exemple, nous rappelle aussi que l’accouchement à domicile était la règle avant-guerre. Alors qu’aujourd’hui, les naissances se concentrent dans les communes sièges de maternités.
Par ailleurs, le codage du lieu de naissance est relatif à la géographie de l’époque. Le pays de naissance est généralement indiqué en clair, mais pas toujours. C’est le cas en particulier de l’Algérie avant son indépendance, que l’on peut (et doit) repérer par les codes Insee 91352, 92352, 93352 (anciens départements d’Alger, Oran et Constantine) et 99352 (Algérie).
Si l’on ne considère que le pays de naissance mentionné dans la base, sur les 623 000 défunts nés en Algérie avant l’indépendance, un tiers sont décrits sans pays de naissance mentionné. L’équipe data.gouv.fr recode, dans son fichier parquet national, le pays de naissance en ‘FRANCE METROPOLITAINE’ quand il est vide, ce qui ne convient pas dans ce cas de figure [NDR : correction effectuée depuis].
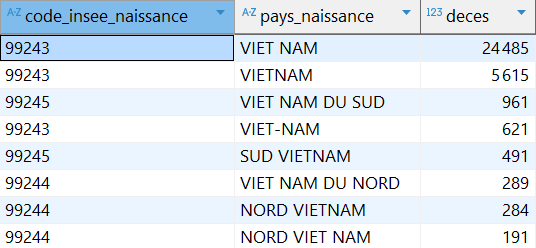
Pour de nombreux pays, il est également intéressant de construire un libellé alternatif, simplifié. Par exemple, recoder toutes ces occurrences en un seul libellé ‘VIETNAM’ :
De même, les dates de naissance ne sont pas toujours précises : parfois le jour manque (codé 00), le mois manque aussi (codé 00), ou alors l’année est fantaisiste.
Cette requête liste les défunts dont la date de naissance n’est pas valide au regard de l’informatique :

0,6 % des dates de naissance sont ainsi approximatives ou inconnues, ce qui est certes très faible. Mais cette part monte à 5 % pour les personnes nées en Algérie avant l’indépendance (et 3 % pour le Vietnam avant 1956).
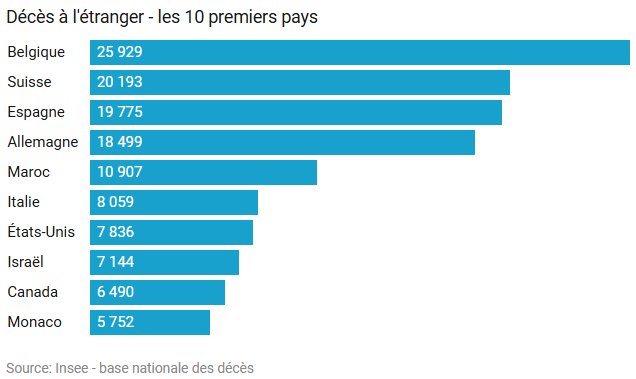
Les décès à l’étranger
La base nationale des décès accueille toutes les personnes décédées en France, quels que soient leur nationalité ou leur statut (résident ou touriste). En effet, pour tout décès survenu en France, un médecin établit un certificat et la mairie concernée un acte de décès.
À l’inverse, l’Insee reçoit aussi les actes de décès à l’étranger de citoyens français, que lui transmettent par exemple les consulats. Ces actes intègrent eux aussi la base, mais sans garantie d’exhaustivité.
Le fichier des oppositions
Les ayant droit ou héritiers peuvent demander l’occultation des informations concernant leurs défunts. Toutefois, cette opposition ne s’applique légalement qu’aux fichiers rediffusés, et pas à la base que l’Insee met lui-même en ligne.
L’Insee reçoit environ une demande d’opposition par mois. Elles sont aujourd’hui au nombre de 1 818 (cf. le fichier accessible sur cette page).
730 oppositions, un peu moins de la moitié, concernent des doublons dans la base des décès, doublons pour lesquels le n° d’acte, la commune et la date de décès sont identiques, mais où le nom, le prénom, le lieu de naissance, parfois le sexe (?) diffèrent. Tout se passe comme si les ayants droit, confrontés à une information brouillée, souhaitaient carrément tout effacer, même si l’un des enregistrements est correct.
Les 2/3 des défunts concernés par une opposition sont nés à l’étranger.
Comment produire une base plus propre ?
Les constats développés ici m’ont conduit à produire une base nettoyée et enrichie de nouvelles informations :
- Suppression de 220 000 doublons,
- Recodage simplifié du pays de naissance,
- Création de vrais champs temporels de type date, permettant de calculer un âge au décès. Quand le jour manque, il est conventionnellement fixé à 15 ; quand le mois manque, le milieu de l’année est retenu ; création associée d’une variable indicatrice du caractère de flou des dates ;
- Prise en compte de l’encodage variable des fichiers annuels (utf-8 pour les plus récents, iso-8859 pour les plus anciens) ;
- Base triée pour un format parquet de compression optimisée.
Cette nouvelle base est accessible en open data (sur data.gouv.fr), tout comme le script qui la (re)génère (puisque la mise à jour des données de base est mensuelle, chaque mois, de l’ordre de 50 000 décès s’y rajoutent). Les oppositions sont prises en compte, et donc retirées.
Pour ce faire, je suis parti des fichiers txt annuels et mensuels mis à disposition par l’Insee sur data.gouv.fr, car dans le fichier parquet de l’équipe data.gouv.fr, le pays de naissance était transformé de façon parfois erronée [NDR : correction effectuée depuis]. Cela me permet aussi de mieux gérer l’encodage variable des fichiers sources.
L’API de data.gouv.fr permet d’en lister les URL automatiquement (contrairement aux csv présentés sur insee.fr), ce qui simplifie et pérennise le script de génération.
Pas de Python ni de R, du pur SQL DuckDB, bien plus léger, lisible et élégant !
Pour en savoir plus
- Arrêt de la Commission d’accès aux documents administratifs
- Fichiers annuels et mensuels diffusés par l’Insee sur data.gouv.fr
- Fichiers mensuels, anuels et décennaux diffusés par l’Insee sur insee.fr
- Base nationale au format parquet, préparée par l’équipe data.gouv.fr
- Base nationale nettoyée au fomat parquet, préparée par icem7
bonjour,
# En mapinulant le fichier deces.parquet, je me suis aperçu que la colonne
# commune_naissance contenait pour certaines valeurs des
# caractères non imprimables
library(arrow)
library(duckdb)
deces_df <- read_parquet("deces.parquet")
jeu_deboublonne <- sql_query("
SELECT DISTINCT (date_deces, code_insee_deces, nom, prenoms) , *
FROM deces_df
;
")
# Error in `dbSendQuery()`:
# ! embedded nul in string: 'SAN ANTONIO DI SUSA\0\0\0\0\0\0\0\0\0\0\0'; to strip nuls when converting from Arrow to R, set options(arrow.skip_nul = TRUE)
# Run `rlang::last_trace()` to see where the error occurred.
####
# CORRECTION DU CODE
####
library(duckdb)
library(stringi)
library(arrow)
options(arrow.skip_nul = TRUE)
# pour ne pas déclencher une errreur si des caractères non imprimables
# sont trouvés, un avertissement est émis
deces_df <- read_parquet("deces.parquet")
# SUPPRESSION caratère non imprimable
deces_df$commune_naissance <- stri_replace_all_regex(deces_df$commune_naissance, "[[:cntrl:]]", "")
jeu_deboublonne <- sql_query("
SELECT DISTINCT (date_deces, code_insee_deces, nom, prenoms) , *
FROM deces_df
;
")
le code fonctionne
cordialement
Bonjour,
et merci pour cette remarque précise et judicieuse, R se montre en effet sensible à ces caractères invisibles.
Je les ai nettoyés et ai mis à jour la ressource sur data.gouv.
J’ai testé votre requête directement sur le parquet, cela évite de charger toute la base en mémoire dans un dataframe (c’est tout l’intérêt de DuckDB) :
# Connexion DuckDB
con <- dbConnect(duckdb::duckdb()) # Requête directe sur le fichier Parquet jeu_dedoublonne <- dbGetQuery(con, " SELECT DISTINCT ON ( date_deces, code_insee_deces, nom, prenoms) * FROM read_parquet('base_deces.parquet') ") # Fermer la connexion dbDisconnect(con, shutdown = TRUE)