Un fichier parquet bien construit oriente le requêteur en lui disant d’abord où ne pas aller. Plus il ferme de portes à votre requête SQL, moins elle se perd en explorations inutiles, plus vite elle avance vers l’essentiel.
C’est exactement la logique du data skipping : éviter de lire ce qui ne sert à rien.
Pour cela, le format parquet dispose de trois leviers complémentaires — dont deux sont bien connus, et un troisième, plus discret : les filtres de Bloom.
Premier levier : des colonnes physiquement séparées.
Parquet est un format orienté colonnes. Si une requête ne porte que sur 3 colonnes d’un fichier qui en contient 20, alors les 17 autres ne seront tout simplement jamais lues.
Deuxième levier : des lignes regroupées en blocs (« row groups »).
Chaque row group est accompagné de statistiques simples, notamment les valeurs minimale et maximale de chaque colonne. Si une requête filtre sur une valeur qui se situe en dehors de cet intervalle, le bloc entier peut être ignoré immédiatement, sans lecture.
Avec des requêtes bien ciblées, ce mécanisme permet souvent d’écarter 90 % du fichier ou plus avant même d’entrer dans le détail des données.

Troisième levier — et c’est le cœur de cet article : les filtres de Bloom.
Si la colonne sur laquelle porte votre condition de filtrage n’est pas triée, les valeurs min-max de chaque row-group donnent souvent une plage trop large pour être utile. Par exemple, vous cherchez une commune de code 31410 et le row group que vous abordez présente dans ses stats une plage allant de 02008 à 88125 : votre 31410 pourrait s’y trouver. Ou pas. Impossible de le savoir sans aller lire les données.
C’est précisément dans ce genre de situation qu’intervient le filtre de Bloom. Bien souvent il pourra vous dire : « la valeur que vous cherchez n’est pas dans ce row group ». Et vous pourrez le croire.
En revanche, il pourra aussi répondre : « oui, peut-être que cette valeur est présente ». Mais son grand intérêt est qu’il se trompe peu (typiquement 1 à 2 % de « faux positifs ») et qu’il est très rapide à consulter. Il permet ainsi d’éviter de coûteuses recherches.
Son désavantage, puisque qu’il y a toujours un compromis à faire, c’est qu’il alourdit un peu le fichier – comme tout mécanisme d’indexation.
Comment ça marche un filtre de Bloom ?
Par la suite, on va considérer la base Sirene de l’Insee.
Chaque établissement immatriculé en France reçoit un identifiant unique de 14 chiffres, le code « siret » (par exemple : 88942551800012).
Prenons un row group qui décrit 100 000 sirets. Ces 100 000 sirets forment un ensemble (un « set ») que l’on va projeter dans une structure très simple, une suite de bits qui valent soit 0 soit 1.
C’est ainsi que se présente un filtre de Bloom. Pour le dimensionner, son concepteur, Burton Bloom, préconise un ordre de grandeur de 10 bits par élément à indexer. Ainsi, 100 000 sirets seront traités dans un filtre de 1 Mo, ce qui n’est pas grand-chose au regard des bénéfices à en tirer.
Au départ, tous les bits sont à 0, comme le montre l’image suivante (c’est un schéma, je ne figure pas le million de bits, j’en donne une vue simplifiée).

Le premier siret de notre ensemble est traité par k fonctions de hachage (je prends k = 3 dans cette illustration).
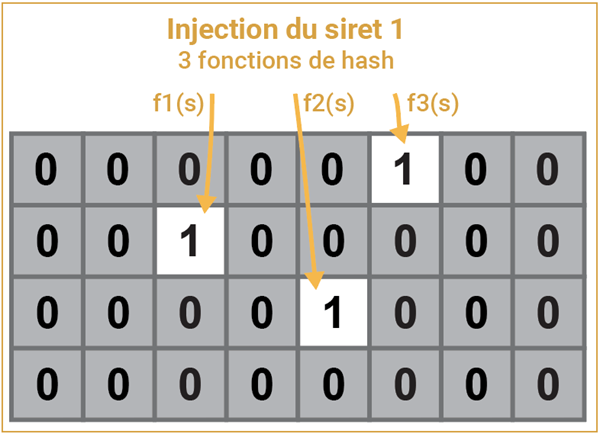
Une fonction de hachage transforme une chaine (comme ici un siret) en un chiffre qui peut être très grand. On va le réduire à un numéro d’ordre dans le filtre en prenant le reste de la division par la taille du filtre. L’image ci-dessus figure un filtre de 32 bits, f3(s) me donne par exemple 325, dont le reste de la division par 32 est 5. La numérotation commence à 0, le 6e bit passe donc à 1.
Trois fonctions de hachage indépendantes réduisent donc le siret considéré à une signature simplifiée de trois entiers, trois bits qui basculent à 1 dans le filtre. Cette réduction fait que la signature d’un siret n’est pas forcément unique. Deux sirets pourraient laisser la même signature, même si c’est rare. En revanche, cas de figure plus fréquent, deux signatures pourront avoir un ou deux bits en commun.
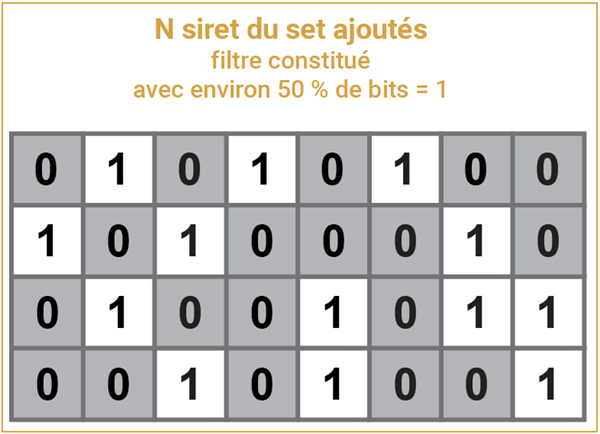
C’est ce qui se passe quand j’injecte le siret 2. Mais la case « 1+ » garde en fait la valeur 1, c’est un bit, il vaut 0 ou 1.

Quand tous les siret de notre ensemble sont traités dans le filtre, on aboutit à une structure semi-pleine (50 % est un bon ordre de grandeur pour un filtre efficace).
Servons-nous maintenant de ce filtre.
J’ai une requête avec une condition simple d’égalité, comme :
WHERE siret = '40759029800011'
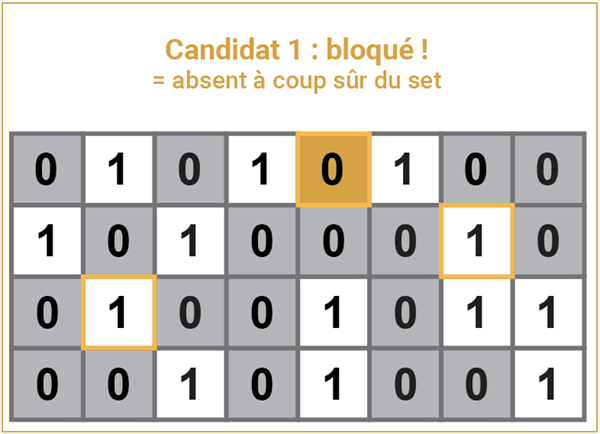
Ce siret est mon candidat 1. J’applique à ce siret les mêmes trois fonctions de hachage que celles qui ont servis à construire le filtre.
Je constate que la signature de ce candidat tape dans un bit bloqué à 0 : je sais alors avec certitude que ce siret 40759029800011 n’est pas dans ce row group. Ma requête peut donc totalement l’ignorer.
Avec une autre condition comme :
WHERE siret = '53775694200018'
je constate que la signature de ce nouveau siret ne touche que des bits à 1. Ce que le filtre de Bloom m’indique ici, c’est que ce siret est « peut-être » dans le row group. Il faudra aller vérifier de plus près.
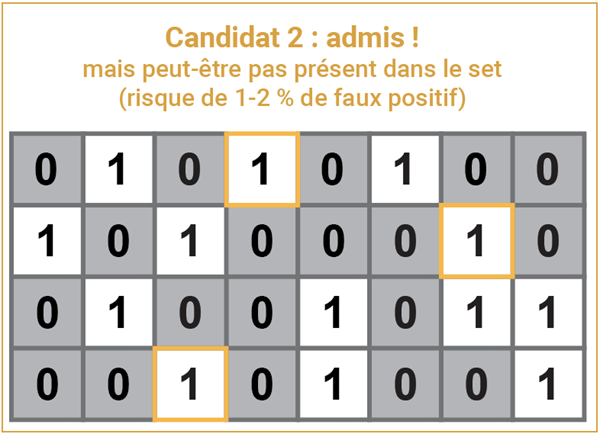
C’est la dimension « probabiliste » du filtre de Bloom. Mais bien construit, de taille suffisante, il ne validera qu’une fois ou deux sur cent un « faux-positif », ce qui est très faible au regard de son énorme potentialité de « data-skipping ».
Première application concrète
Le lecteur et la lectrice perspicaces, surtout si Sirene leur est familier, auront déjà pensé : mais quel intérêt, une base Sirene est déjà triée par Siret ! Les stats min-max de chaque row group permettront d’éliminer tous les row groups sauf le bon. Un filtre de Bloom n’apportera rien de plus.
Mais précisément : pourquoi forcément trier une base Sirene par siret (ou un répertoire Finess par code finess, ou un répertoire de logements par identifiant) ? Quels en sont les avantages et les inconvénients ?
Voici une application pratique avec DuckDB (qui gère les filtres de Bloom) et la base Sirene géolocalisée, présentée sur cette page de la plateforme data.gouv.fr.
C’est un fichier qui pèse 800 Mo et décrit 37 millions d’établissements, avec leurs coordonnées estimées et leur inclusion dans divers zonages administratifs.

Je peux tenter d’interroger directement cette base là où elle est, avec DuckDB ; le lien est stable, c’est bien pratique :
FROM 'https://object.files.data.gouv.fr/data-pipeline-open/siren/geoloc/GeolocalisationEtablissement_Sirene_pour_etudes_statistiques_utf8.parquet'
WHERE siret = '88942551800012' ;
Cette requête prend 2 secondes et renvoie bien une ligne (ouf, c’est le siret d’icem7 !).
En la faisant précéder d’un EXPLAIN ANALYZE, j’obtiens entre autres le volume téléchargé par DuckDB, la bande passante utilisée :
SET enable_external_file_cache = false ; -- désactivation de la mise en cache des requêtes pour faire les bonnes mesures à froid
EXPLAIN ANALYZE
FROM 'https://object.files.data.gouv.fr/data-pipeline-open/siren/geoloc/GeolocalisationEtablissement_Sirene_pour_etudes_statistiques_utf8.parquet'
WHERE siret = '88942551800012' ;
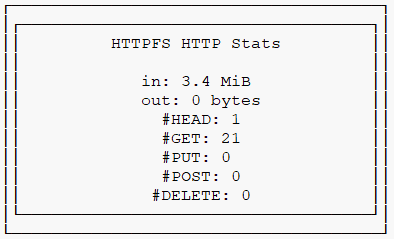
3,4 Mo seulement téléchargés, ce qui explique la rapidité de la requête. On vérifie là une fois de plus l’extraordinaire intérêt du format parquet : je n’ai lu ici que 0,4 % du fichier.
Mais Bloom n’a rien à y voir ici. D’abord parce qu’il n’y a pas dans ce fichier de filtre de Bloom associé à la colonne siret. Ensuite parce qu’étant trié par siret, le fichier indique très vite au moteur DuckDB, par ses métadonnées et ses stats, dans quel row group taper. DuckDB télécharge alors tout le contenu du row group (car je n’ai pas précisé quelles colonnes je voulais), et fait ensuite le tri localement pour trouver le bon siret parmi les 120 000 du row group.
Toutefois, il s’agit d’une base en opendatata, a priori pour faire des analyses. Je ne veux pas m’en servir pour juste trouver de l’info sur un siret (pour cela, il suffit que je le copie/colle dans mon navigateur et j’aurai tout de suite une réponse). Je veux plutôt faire de la stat avec, par exemple de l’analyse géographique, considérer une activité particulière, ou réaliser un appariement pour enrichir un autre fichier.
Que donnerait une requête d’extraction pour la commune de Toulouse ? Spoiler alert : je ne vous recommande pas de le tenter directement sur le fichier en ligne.
Par souci écologique, je poursuis mes explorations en local, après avoir téléchargé la base parquet, que je renomme en sirene_geoloc_0.parquet, et que j’accède via un serveur web local léger (minio), pour bénéficier des stats HTTP de EXPLAIN ANALYZE.
EXPLAIN ANALYZE
FROM 's3://public/sirene_geoloc_0.parquet'
WHERE plg_code_commune = '31555' ;
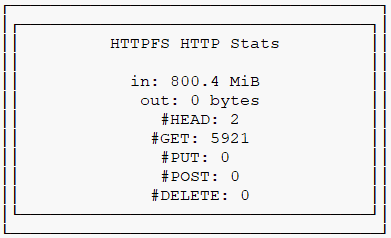
Cette nouvelle requête géographique consomme 800 Mo, en gros l’intégralité du fichier ! Et prend 2 s. Pourquoi ? Parce que le fichier étant trié par siret, code unique grosso modo aléatoire, il ne l’est pas du tout par code commune (ni par département ou région). Dans tous les row groups, je vais avoir un établissement situé à Toulouse. Ma requête doit donc tous les parcourir.
La structure de ce fichier parquet est de fait optimisée pour cibler rapidement un établissement par son siret. Mais elle ne l’est pas pour les autres types de filtrage.
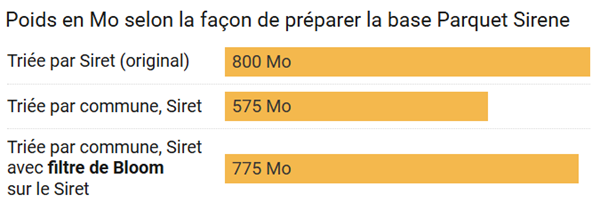
Je prépare une copie de cette base avec un tri différent : code commune d’abord, siret ensuite. Premier constat , sirene_geoloc_1.parquet pèse sensiblement moins, 575 Mo au lieu des 800 Mo de l’original. En effet, la compression de toutes les colonnes géographiques est bien meilleure dès lors que le tri devient géographique.
Cette requête géographique consomme 8 Mo, prend 100 ms, c’est bien mieux qu’avec l’original :
FROM 's3://public/sirene_geoloc_1.parquet'
WHERE plg_code_commune = '31555' ;
Mais celle-ci sur un siret aspire 200 Mo, en 400 ms :
FROM 's3://public/sirene_geoloc_1.parquet'
WHERE siret = '88942551800012' ;
C’est moins pire que les 800 Mo consommés plus haut, mais ça reste quand même beaucoup, 200 Mo.
C’est une question de compromis me direz-vous : on ne peut pas gagner sur tous les tableaux ? Avec Bloom, on va voir que si.
Comment savoir si un filtre de Bloom est présent ?
DuckDB permet d’accéder aux métadonnées d’un fichier parquet, en les détaillant par row group. Une colonne bloom_filter_length répond à notre curiosité.
FROM parquet_metadata('s3://public/sirene_geoloc_1.parquet')
SELECT row_group_id, bloom_filter_length
WHERE path_in_schema = 'siret'
ORDER BY bloom_filter_length DESC ;
row_group_id | bloom_filter_length |
0 | NULL |
1 | NULL |
2 | NULL |
… | … |
300 | NULL |
Je ne vois que des valeurs NULL pour tous les row groups, pas de Bloom filter ici.
C’est que DuckDB ne les génère automatiquement que pour les colonnes de cardinalité faible ou moyenne, bref avec pas trop de valeurs distinctes. Pour le forcer à en créer un pour la colonne siret, (à défaut pour l’heure de pouvoir lui demander explicitement), je peux préciser un paramètre au moment de la génération d’une copie parquet :
COPY 's3://public/sirene_geoloc_1.parquet'
TO 's3://public/sirene_geoloc_2.parquet' (COMPRESSION zstd, DICTIONARY_SIZE_LIMIT 130_000, BLOOM_FILTER_FALSE_POSITIVE_RATIO 0.05) ;
Augmenter la taille de DICTIONARY_SIZE_LIMIT va permettre de forcer l’encodage de la colonne siret à partir d’un dictionnaire, et ce faisant dans DuckDB conduire à la génération d’un Bloom filter. C’est la seule façon de faire pour le moment, en attendant mieux. Par défaut, ce paramètre correspond à 20 % du nombre de lignes dans un row group. Je l’ai relevé à 100 %.
BLOOM_FILTER_FALSE_POSITIVE_RATIO : ce paramètre vaut par défaut 0,01 (1 % de faux positifs), je l’ajuste à 5 % pour réduire la taille des filtres de Bloom, sans pour autant nuire à leur efficacité.
sirene_geoloc_2.parquet remonte à 775 Mo, du fait de l’ajout d’un dictionnaire et des filtres de Bloom, mais pèse un peu moins que l’original.
Testons nos deux requêtes-types avec ce fichier parquet indexé par filtres de Bloom sur le siret.
La requête géographique consomme 8 Mo pour 100 ms.
FROM 's3://public/sirene_geoloc_2.parquet'
WHERE plg_code_commune = '31555' ;
Celle par siret consomme 45 Mo pour 100 ms :
FROM 's3://public/sirene_geoloc_2.parquet'
WHERE siret = '88942551800012' ;
Ceci bien que le fichier lu ne soit pas trié par siret. Les filtres de Bloom sont bien entrés en action !
Pour mieux le comprendre, cette fonction nous donne précisément les row groups pour lesquels le filtre de Bloom siret a répondu « niet : le siret que tu cherches n’est pas ici » :
FROM parquet_bloom_probe('s3://public/sirene_geoloc_2.parquet', 'siret', '88942551800012')
SELECT row_group_id, bloom_filter_excludes
ORDER BY bloom_filter_excludes ;
bloom_filter_excludes = false veut dire : je n’exclus pas ce row group, le siret recherché est peut-être dedans. Cela ne concerne que 7 row groups sur 300.
row_group_id | bloom_filter_excludes |
70 | false |
53 | false |
133 | false |
299 | false |
73 | false |
103 | false |
190 | false |
3 | true |
8 | true |
… | … |
300 | true |
bloom_filter_excludes = true veut dire : le siret que tu recherches n’est pas là, c’est certain.
293 row groups sur 300 ont ainsi pu être « sautés », c’est absolument remarquable.
45 Mo lus lors de cette requête sur code siret : c’est en fait la taille cumulée des Bloom filters de tous les row groups pour la colonne siret. C’est déjà bien mieux que les consommations précédentes. De plus, grâce à la mise en cache automatique par DuckDB, les requêtes suivantes ne l’extrairont plus du fichier parquet : chaque filtre de Bloom reste chargé en mémoire, son usage devient instantané.
Résumons dans ce tableau ces différents tests réalisés en local :
Fichier | Nature | Filtre siret | Filtre commune | Siret absent |
Geoloc_0 | Originel | 4 Mo / 100 ms | 800 Mo / 1,7 s 0-2 Mo / 100 ms | 2 Mo / 100 ms 0-2 Mo / 100 ms |
Geoloc_1 | Trié par commune | 200 Mo / 400 ms 1 Mo / 100 ms | 8 Mo / 100 ms 1-2 Mo / 100 ms | 200 Mo / 350 ms 0-5 Mo / 100 ms |
Geoloc_2 775 Mo | Trié par com. et siret avec un filtre Bloom siret | 45 Mo / 130 ms 2-8 Mo / 100 ms | 8 Mo / 100 ms 1-2 Mo / 100 ms | 43 Mo / 150 ms 5 Mo / 100 ms |
La 2e ligne de chaque mesure teste un nouveau siret ou un nouveau code commune. Les métadonnées et données automatiquement mises en cache par DuckDB expliquent la nette accélération dès la seconde lecture.
Ce graphique résume l’essentiel : comment consommer moins de bande passante avec une stratégie de tri et d’indexation, pour accélérer globalement les différentes requêtes possibles.

Et en accès distant, qu’est-ce que cela donne ?
J’ai placé sirene_geoloc2.parquet sur data.gouv.fr, vous pourrez ainsi le tester par vous-même :
FROM 'https://static.data.gouv.fr/resources/bloom-filters-sirene-1/20260107-165359/sirene-geoloc-2.parquet'
WHERE plg_code_commune = '31555' ;
FROM 'https://static.data.gouv.fr/resources/bloom-filters-sirene-1/20260107-165359/sirene-geoloc-2.parquet'
WHERE siret = '88942551800012' ;
Voici mes mesures comparées sur cet accès en ligne. Les temps dépendent du moment de la journée et de la vélocité variable de la plateforme data.gouv (plus rapide le soir qu’en journée).
Fichier | Nature | Filtre siret | Filtre commune | Siret absent |
Geoloc_0 | Originel | 4 Mo / 700 ms | 800 Mo / 50 s 0-2 Mo / 100 ms | 2 Mo / 1 s 0-2 Mo / 100 ms |
Geoloc_2 En ligne | Trié par com. et siret avec un filtre Bloom siret | 45 Mo / 2-10 s 2-8 Mo / 100 ms | 7 Mo / 2-5 s 1-2 Mo / 100 ms | 43 Mo / 1,6 s 5 Mo / 100 ms |
Conclusion : avec une infrastructure vraiment rapide (de type S3), des fichiers parquet bien préparés, et des clients intelligents (cache, data-skipping) comme DuckDB, il devient envisageable de travailler de grosses bases en ligne.
Est-ce gênant de ne pas trier par siret si l’on veut faire des jointures ?
Contrairement à l’intuition, apparier deux tables par siret n’ira pas plus vite si ces tables sont triées selon le champ de jointure. DuckDB procède à un hachage des valeurs de la clé de jointure, le tri n’apporte rien.
Quand les filtres de Bloom sont-ils utiles ?
Ils ne sont pas la solution à tous les problèmes d’indexation. Tout d’abord, ils n’opèrent qu’à partir de conditions d’égalité stricte, de type = ou IN.
Ils fonctionnent particulièrement bien sur les colonnes de haute cardinalité comme des identifiants uniques, qu’on ne veut pas retenir comme critère de tri initial du fichier parquet.
Mais ils s’appliquent aussi à des identifiants faiblement répétés.
Considérons une variante de la base Sirene des établissements, plus détaillée, qui renseigne des adresses, décrites en clair et aussi à partir d’un identifiant d’adresse normalisé, le code BAN (Base adresse nationale). Cette base plus riche (2 Go) est également disponible sur data.gouv.fr. Je l’ai récupérée, je joue avec en local.
Il y a dans cette base Sirene 2 millions d’adresses distinctes.
FROM 's3://public/StockEtablissement_utf8.parquet'
SELECT count(*) nb_etabs,
count(DISTINCT identifiantAdresseEtablissement) nb_adresses ;
nb_etabs | nb_adresses |
42 427 537 | 2 028 181 |
Ma question : quels sont les établissements qui partagent une même adresse postale, par exemple tous ceux figurant dans un même immeuble à Toulouse ?
FROM 's3://public/StockEtablissement_utf8.parquet'
SELECT siren
WHERE identifiantAdresseEtablissement = '315552766_B' ;
À partir du fichier d’origine, sans filtre de Bloom, la requête consomme 150 Mo, et s’exécute (en local) en 300 ms.
Je crée une nouvelle version de cette base, gardant cette fois-ci le tri par siret, mais ajoutant un filtre de Bloom sur identifiantAdresseEtablissement.
Je relance la même requête :
FROM 's3://public/StockEtablissement_utf8_bf.parquet'
SELECT siren
WHERE identifiantAdresseEtablissement = '315552766_B' ;
Cette fois ci, la consommation est de 26 Mo (7 fois moins), et le temps d’exécution de 100 ms (3 fois moins).
Le filtre de Bloom élimine 336 row groups sur 343.
La bande passante consommée correspond peu ou prou à la taille des filtres de Bloom pour cette colonne :
FROM parquet_metadata('s3://public/StockEtablissement_utf8_bf.parquet')
SELECT sum(bloom_filter_length)
WHERE path_in_schema = 'identifiantAdresseEtablissement' ;
-> 22 Mo
Conclusion
Présentée dès 1970 par Burton Howard Bloom, cette méthode élégante a profondément marqué les systèmes informatiques modernes. Aujourd’hui, les filtres de Bloom sont omniprésents : ils servent à écarter des recherches de films inexistants, à vérifier qu’un pseudo n’est pas déjà pris, ou encore qu’une adresse électronique n’appartient pas à une liste de spammeurs.
C’est une technique probabiliste — elle ne donne pas toujours de certitude absolue — mais elle permet de gagner énormément de temps. Un filtre de Bloom ne cherche pas à confirmer qu’une donnée est présente ; il excelle surtout à affirmer qu’elle ne l’est pas. Et cette capacité à dire rapidement non est souvent bien plus précieuse que la capacité à dire oui.
Dans le contexte de l’analyse statistique, les filtres de Bloom sont particulièrement pertinents pour indexer des colonnes non triées, à forte cardinalité, lorsque les statistiques min–max deviennent trop grossières pour être utiles. Ils ajoutent une couche d’information minimale mais décisive, qui permet d’écarter très tôt de larges portions de données sans les lire.
Plus largement, leur usage invite les producteurs de données à se projeter dans les requêtes que les utilisateurs vont réellement formuler, et à tirer parti des subtilités du format Parquet — un format pensé pour être interrogé à distance, efficacement, sans téléchargement intégral.
À ce jour, DuckDB est l’un des rares outils à exploiter pleinement les filtres de Bloom dans Parquet, aussi bien en lecture qu’en écriture. Il reste encore des marges de manœuvre pour affiner leur paramétrage, mais gageons que ces réglages plus fins verront bientôt le jour… lobbying en cours.
Bonjour Eric,
C’est toujours un plaisir de vous lire et je ne peux que vous remercier pour la promotion que vous faites de Parquet et DuckDB !
Il me reste une petite question : combien de temps prend la copie d’un fichier parquet sans filtres dans un fichier avec ?
D’avance merci et je profite de l’occasion pour vous souhaiter une excellente année 2026 !
Bonjour Jean-Yves,
et merci, excellente nouvelle année de même !
L’intégration d’un filtre de Bloom n’est pas spécialement consommatrice, les tris le sont davantage.
Merci pour l’explication très claire et les exemples qui donnent des ordres de grandeur. Une bonne ressource lorsqu’on fait de l’ingénierie de fichiers Parquet.
Merci Sylvain, venant d’un expert+++ comme toi, cela me fait bien plaisir !
Intéressants les filtres de Bloom, merci pour cette très bonne illustration.
Question en passant, je remarque l’utilisation de ‘identifiantAdresseEtablissement’ à quoi cela correspond-il ? Je trouve des données dans ce genre (ma préférée étant « 440212ttrrt_B ») :
« 955851080_B »,
null,
« 830470045_B »,
« [ND] »,
« 590430340_B »,
« [ND] »,
« 972090613_B »,
« 974134jkw_B »,
« 263627865_B »,
« [ND] »,
« [ND] »,
null,
« 784400117_C »,
« 593860140_C »,
« 150141800_B »,
« 440212ttrrt_B »,
« 766811280_B »,
« 831375680_B »,
Bonjour,
et merci pour vorte appréciation !
Les identifiants de la base adresse nationale ne me sont pas famliliers, mais ça ressemble à un code commune + un identifiant interne et/ou un hash d’unicité.
La dernière lettre pourrait être un suffixe permettant de distinguer plusieurs établissements à la même adresse.