Cet article technique inaugure une série consacrée à la flexibilité du langage statistique R (la série sera donc fournie !)
Je vais vous montrer à partir de cas concrets et pratiques, comment gagner du temps, récupérer facilement des ressources sur le web et les mettre en forme pour les adapter à vos besoins de traitement et d’analyse. Ici, vous ne trouverez point d’exemples hors-sol ou de tutoriels traduits hâtivement de l’américain. Ma connaissance de R s’est nourrie de la nécessité de résoudre des défis du quotidien, dans un métier – statisticien – que j’exerce depuis 30 ans.
Je privilégie la syntaxe R « moderne », issue du cadre Tidyverse créé par Hadley Wickham. Cette façon de programmer est élégante et didactique, cohérente et facile à assimiler.
Commençons avec des données Insee : l’institut statistique français vient de mettre en ligne une série de près de 10 années sur les naissances domiciliées, à la commune, en géographie 2020. Ces données sont proposées au format xlsx ou csv.
1 - Acquisition des données Insee d'État civil
# début du script library(tidyverse) url_ec = "https://www.insee.fr/fr/statistiques/fichier/1893255/base_naissances_2019.zip"
library(curl) xlsfile = str_replace(basename(url_ec), ".zip", ".xlsx") # "base_naissances_2019.xlsx" tempzip = tempfile() curl_download(url_ec, tempzip) # télécharge le zip xlsfile = unzip(zipfile = tempzip, files = xlsfile) # extrait le xlsx
library(readxl) tb_com = read_excel(xlsfile, sheet = 1, skip = 5)
Voici les données chargées dans tb_com (ici les 20 premières lignes) :
Comme on le voit, cette table présente 4 variables caractères et 10 variables numériques.
library(janitor) tb_com = tb_com %>% clean_names() # nettoie les noms de colonne => minuscules, sans blanc ni accent
2) Agrégation par département
Je voudrais maintenant regrouper ces naissances par département. Comment sommer ces 10 colonnes numériques sans trop me fatiguer ?
tb_dep <- tb_com %>% group_by(dep) %>%
summarise_if(is.numeric, sum, na.rm = TRUE)
# introduction d'un filtrage préalable sur une région (Bretagne, de code '53')
tb_dep <- tb_com %>% filter(reg == '53') %>%
group_by(dep) %>%
summarise_if(is.numeric, sum, na.rm = TRUE)
Voici le résultat de la dernière requête, filtrée sur la région Bretagne :
J’entends déjà les bons élèves : « depuis la version dplyr 1.0, summarise_if est dépréciée, il faut utiliser across à la place ». Que nenni ! Le big boss Hadley Wickham me l’a personnellement confirmé (car nous sommes intimes) : « there’s no rush to stop using …_if(); it’ll be around for at least several more years before we even begin to consider if it should be deprecated ».
Il faut dire que, pour l’instant, summarise(across…) est 5 fois plus lent que summarise_if, mais cela devrait s’améliorer très bientôt avec dplyr 1.1…
tb_dep <- tb_com %>% group_by(dep) %>%
summarise(across(where(is.numeric), sum, na.rm = TRUE))
Mais c’est moins joli/intuitif, nous réserverons across pour des cas d’usage plus pointus. 3 - Ajout des données par arrondissement municipal
Le fichier excel d’origine comporte deux onglets, et le second détaille les naissances par arrondissement des communes de Paris, Lyon et Marseille. Nous allons ajouter ces lignes à notre table communale, en prenant soin d’ajouter une colonne catégorielle pour distinguer 3 types de territoire : communes simples (C), communes divisées en arrondissements (D), arrondissements (A).
# ajout d'une nouvelle colonne type_terr
tb_com <- tb_com %>% mutate(type_terr =
if_else(codgeo %in% c('75056','13055','69123'), 'D', 'C'),
.after = 'codgeo')
# lecture des données par arrondissement
tb_arm <- read_excel(xlsfile, sheet = 2, skip = 5) %>%
clean_names() %>%
mutate(type_terr = 'A', .after = 'codgeo')
# concaténation
tb_com <- tb_com %>% bind_rows(tb_arm) %>%
arrange(codgeo) # tri par codgeo
# table des communes
tb_com %>% filter(type_terr %in% c('C','D'))
# table des communes/arm
tb_com %>% filter(type_terr %in% c('C','A'))
4 - Transposition/simplification : mise en évidence de l'axe temporel
Notre table avec 10 colonnes numériques ne répond pas aux critères des statisticiens exigeants que nous sommes. Ces 10 colonnes, on le voit bien, relèvent de la même notion, du même indicateur, seule l’année les différencie.
Une table maniable comprend un nombre de colonnes réduit et stable dans le temps. L’ajout d’un nouveau millésime de données ne doit pas en perturber la structure. On va donc chercher à introduire une nouvelle colonne annee, pour ne garder qu’une seule variable numérique naisd.
tb_com_tr <- tb_com %>% select(-libgeo) %>% # suppression de libgeo pour alléger
pivot_longer(cols = starts_with('naisd'),
names_to = "annee", values_to = "naisd")
# par défaut, la nouvelle variable annee reprend les noms de colonnes numériques
# il nous faut la corriger en remplaçant la racine naisd par 20, ainsi naisd19 => 2019
tb_com_tr <- tb_com_tr %>% mutate(annee = str_replace(annee, "naisd", "20"))
Voilà qui nous amène à une table de 350 000 lignes (ici les 20 premières) :
tb_reg <- tb_com_tr %>% filter(type_terr %in% c('C','D')) %>%
group_by(reg, annee) %>%
summarise(naisd = sum(naisd, na.rm = TRUE))
tb_dep53 <- tb_com_tr %>% filter(reg == '53') %>%
group_by(dep, annee) %>%
summarise(naisd = sum(naisd, na.rm = TRUE))
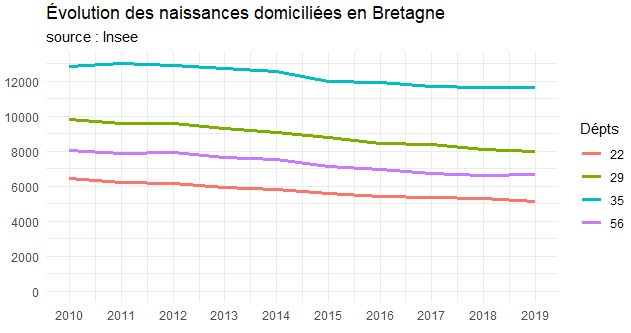
ggplot(tb_dep53 %>% mutate(annee=as.numeric(annee))) +
aes(x = annee, y = naisd, colour = dep) +
geom_line(size = 1.2) +
labs(title = "Évolution des naissances domiciliées en Bretagne",
color = "Dépts", subtitle="source : Insee", x = "", y = "" ) +
theme_minimal() +
expand_limits(y = 0) +
scale_x_continuous(breaks = seq(2010, 2019, 1)) +
scale_y_continuous(breaks = seq(0, 14000, 2000))
5 - Export du résultat
Il ne nous reste plus qu’à stocker le résultat de ce traitement. Une base de données serait une destination appropriée, pour en faciliter le partage et la jointure avec d’autres jeux de données ou référentiels géographiques. Je vous montrerai comment procéder dans un article ultérieur.
# export du résultat
# par exemple en xlsx
library(openxlsx)
write.xlsx(tb_com_tr, file = 'etatcivil_comarm2020.xlsx',
sheetName = "comarm2020", overwrite = TRUE)
# ou en csv
write.csv(tb_com_tr, file = "etatcivil_comarm2020.csv",
row.names = FALSE)
A partir de là, il est possible de cartographier ses données avec par exemple l’excellent outil France découverte ! Et même de produire une belle animation temporelle. L’Insee les a mis en ligne aussi sur Statistiques locales.
rm('tb_arm','tb_com','tb_dep','tb_reg')
unlink(c(tempzip,xlsfile))
N’hésitez pas à laisser un commentaire, j’y répondrai volontiers. Je propose également des transferts de connaissance et d’expertise sur mesure (R/tidyverse, certification RStudio en cours), à l’issue desquels vous aurez gagné en autonomie et idées d’explorations nouvelles !
Super papier très synthétique et clair en même temps.
Merci pour votre lecture attentive et ce commentaire sympathique !