Parquet est un format ouvert de stockage de jeux de données. Créé en 2013 par Cloudera et Twitter, longtemps réservé aux pros du big data, il a beaucoup gagné en popularité ces derniers mois. Bien plus compact, super-rapide à lire, compris par davantage d’outils, Parquet est devenu une alternative crédible à l’omniprésent CSV.
C’est un standard ouvert, comme le CSV, qui prend les données telles qu’elles sont collectées, en simples tables de lignes et de colonnes. Si CSV empile des lignes, Parquet raisonne d’abord en colonne : il les distingue, les catégorise selon leur type, documente leurs caractéristiques fines. Cela rend les données plus faciles à manipuler, plus rapides à parcourir. Et comme elles sont intelligemment compressées, elles prennent bien moins de place de stockage, jusqu’à 10 fois moins qu’un fichier texte délimité !

Parquet sait aussi organiser l’information en groupes de milliers de lignes, voire en fichiers distincts, partitionnés, ce qui accélère les requêtes en les dirigeant plus vite vers les seules données pertinentes pour le traitement désiré. La richesse de son dictionnaire de métadonnées est d’une efficacité redoutable, au niveau de celles des index d’une base de données.
À rebours du paradigme classique de R ou Python, il n’est plus nécessaire de charger toute une table en mémoire pour l’analyser, les données sont lues uniquement là où elles sont utiles, sans aucune conversion ou recopie (c’est le principe de localité).
Des avantages incontestables par rapport à CSV
Résumons les deux points forts de Parquet par rapport au format CSV :
- un fichier Parquet a la taille d’un CSV compressé, il prend jusqu’à dix fois moins de place de stockage.
- Il est parcouru, décodé et traité bien plus rapidement par les moteurs de requêtes analytiques.
Dernier avantage : Parquet sait modéliser des types complexes, une colonne comprenant par exemple une structure hiérarchique, un contenu JSON ou le champ géométrique de nos couches SIG (cf. plus loin le projet GeoParquet).
Encore faut-il savoir créer et lire le format Parquet
Jusqu’à il y a peu, seuls des outils très spécialisés permettaient de générer ou lire le format Parquet. En quelques mois, la donne a radicalement changé. Le vaste projet Apache Arrow, porté à partir de 2016 par Wes McKinney (le créateur de la librairie Python/Pandas) et des dizaines de développeurs majeurs du monde de la datascience, est sans nul doute à l’origine de cette accélération.
La plupart des outils analytiques de la datascience, jusqu’à JavaScript dans le navigateur, lisent les formats Parquet et son jeune cousin Arrow en s’appuyant sur un noyau commun de routines C++ développées dans le cadre du projet Apache Arrow.
Enfin, le formidable moteur portable DuckDB met à la portée de n’importe quel PC les performances d’un moteur de base de données traditionnel sur serveur. DuckDB est désormais, avec des données Parquet, plus rapide qu’une base PostgreSQL pour les requêtes d’analyse.
R offre un environnement efficace pour travailler avec Parquet
Votre tableur favori ne propose pas encore de fonction « Enregistrer sous .parquet », mais cela ne saurait tarder. Pour aller au plus vite, ce classeur Observable en ligne vous permet de le faire : il vous invite à téléverser un CSV, le type des colonnes tel que deviné vous est présenté, vous pouvez télécharger la version .parquet de votre fichier et déjà admirer la belle réduction de taille.
Pour visualiser le contenu d’un fichier Parquet, à l’opposé, Tad est un utilitaire libre multiplateforme efficace et véloce ; il autorise même les filtrages et les agrégations. À vous de jouer !
Les convertisseurs en ligne CSV => Parquet sont toutefois limités : à l’évidence par la taille des CSV que vous pouvez téléverser (quelques dizaines de Mo), et parfois parce qu’ils « typent » incorrectement certaines colonnes : vos codes département ou commune se retrouveront amputés du 0 initial, ou pire, une erreur surviendra parce qu’une colonne de codes département sera intuitée numérique au vu des premières lignes, mais produira une erreur à l’apparition des 2A ou 2B des départements Corse.
Pour l’heure, R offre un environnement très efficace pour créer des fichiers Parquet (Python aussi, sans doute). La librairie R arrow fait l’essentiel du travail, avec vélocité et robustesse.
Le fichier des migrations résidentielles : un CSV de 2 Go qui devient facile à manipuler converti en Parquet
Nous allons explorer les avantages du format Parquet à partir d’une table respectable de 20 millions de lignes et 33 colonnes. L’Insee met à disposition la base des migrations résidentielles, issue du recensement de la population, sous deux formats, CSV zippé et .dbf. Le format dbf (DBASE) me rappelle de vieux souvenirs, je ne sais pas qui l’utilise encore… J’espère convaincre mes amis de l’Insee de remplacer un jour ces .dbf par des .parquet !
Chaque résident se trouve comptabilisé dans ce tableau qui résulte d’une ventilation selon une trentaine de caractéristiques de la personne ou de son ménage : commune de résidence et résidence un an avant, CSP, tranche d’âge, type de logement, etc.
Une ligne correspond à un croisement de caractéristiques, elle peut regrouper plusieurs personnes. La colonne IPONDI en donne le nombre : comme il s’agit d’une estimation, IPONDI est en pratique une valeur décimale. C’est la seule colonne numérique, toutes les autres sont des catégories qualitatives d’une nomenclature : code commune, code CSP, etc.
Voici un aperçu de ce CSV, on reconnait le délimiteur français (;), et des valeurs qui peuvent commencer par un 0. Ce CSV n’est pas si simple à afficher, car peu de programmes peuvent ouvrir un fichier texte de 2 Go. J’utilise EmEditor dont la version gratuite fait cela en un clin d’œil.
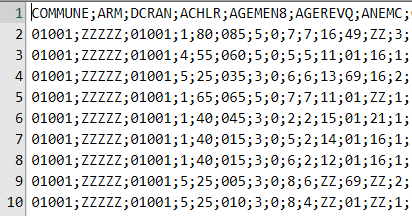
J’ai rencontré plusieurs personnes s’étant bien pris la tête avec un tel fichier. Dans R ou Python, il faut le charger en entier en mémoire, dont l’occupation peut atteindre en pointe les 10 Go : c’est difficilement supportable, et inenvisageable quand l’environnement de travail R est sur serveur et multi-utilisateurs. On s’en sort habituellement en chargeant les données dans une base comme PostgreSQL, ce qui demande pas mal d’écriture, de temps de chargement et oblige à dupliquer les données.
Dans R, les quelques lignes suivantes assurent la conversion vers Parquet, une fois pour toutes, en moins d’une minute.
library(tidyverse)
library(arrow)
library(data.table)
write_parquet(
fread("data/FD_MIGCOM_2019.csv") |>
mutate(across(-IPONDI, as.factor)),
"data/FD_MIGCOM_2019.parquet"
)
# data.table::fread est très efficace pour charger des gros CSV (50 s ici)
# IPONDI est la seule col. numérique, les autres seront typées factors plutôt que string
# write_parquet génére l'équivalent Parquet du CSV en entrée
La version Parquet ne fait plus que 200 Mo, dix fois moins que le CSV de départ. Et elle est directement utilisable avec peu de mémoire, y compris en contexte multi-utilisateurs, aussi facilement qu’une table dans une base de données. En raison de sa nature de standard ouvert, elle a l’avantage supplémentaire de pouvoir être lue par un grand nombre d’outils analytiques.
Les colonnes caractères de nomenclature doivent être typées avec soin
Attardons-nous sur le typage des colonnes qualitatives, car c’est un important facteur d’optimisation des fichiers Parquet. Une colonne de type caractère comprenant les codes souvent répétés d’une nomenclature peut être décrite de façon optimisée à partir du dictionnaire de ses valeurs distinctes, et d’un simple n° d’indice, un entier.
Ces colonnes qualitatives « dictionary-encoded » sont bien plus rapides à lire que les colonnes caractères classiques. Pour l’heure, la plupart des outils automatiques de conversion vers Parquet négligent cette structure optimisée. Dans R, dès lors que les « strings » sont convertis en « factors », qui reposent sur la même idée de dictionnaire, on pourra générer un Parquet bien optimisé. En pratique, les requêtes deviennent deux fois plus rapides encore, cela vaut donc le coup d’y penser !
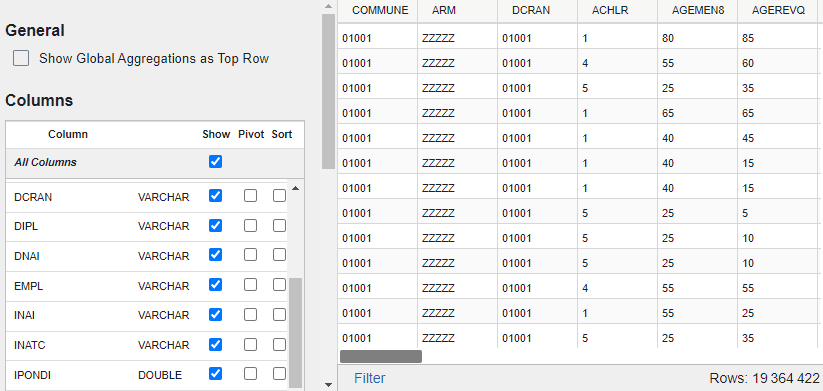
Clic droit sur FD_MIGCOM_2019.parquet dans mon explorateur de fichiers et Tad m’affiche en deux secondes le contenu de cette table Parquet. Chaque colonne apparait bien typée, et mes codes géographiques n’ont pas été altérés :
Comprenons comment optimiser une requête en évitant les chargements ou recopies inutiles
Revenons dans R avec une première requête simple, compter les habitants de Toulouse qui ont changé de logement en un an :
read_parquet("data/FD_MIGCOM_2019.parquet") |>
filter(COMMUNE == '31555' & IRAN != '1') |>
summarise(i = sum(IPONDI))
# 93151
# 7 s
Sept secondes peut sembler un bon résultat pour compter ces 93 151 personnes, mais on peut réduire le temps de calcul à une seconde avec cette variante :
read_parquet("data/FD_MIGCOM_2019.parquet", col_select = c(COMMUNE, IRAN, IPONDI)) |>
filter(COMMUNE == '31555' & IRAN != '1') |>
summarise(i = sum(IPONDI))
# 93151
# 1 s
Ce qui est encore excessif, car la librairie duckdb peut nous faire descendre à 150 ms :
library(duckdb)
con <- dbConnect(duckdb::duckdb())
dbGetQuery(con, "SELECT sum(IPONDI) FROM 'data/FD_MIGCOM_2019.parquet'
WHERE COMMUNE = '31555' AND IRAN <> '1'")
# 93151
# 150 ms
Comment comprendre que l’on arrive à ces performances assez hallucinantes, et l’impact de ces variantes d’écriture sur la charge d’exécution ?
Soyez vigilants avec les pipelines d'instructions chaînées
Dans R et dplyr, le chainage des opérations avec le pipe |> (ou %>%) conduit à séparer les traitements. Ainsi, dans l’écriture suivante; read_parquet() charge en mémoire toute la table avant de la filtrer drastiquement.
read_parquet("data/FD_MIGCOM_2019.parquet") |>
filter(COMMUNE == '31555' & IRAN != '1') |>
summarise(i = sum(IPONDI))
# 93151
# 7 s
Parquet, on l’a vu, encode séparément chaque colonne, si bien qu’il est très rapide de cibler les seules colonnes utiles pour la suite d’un traitement. La restriction suivante apportée au read_parquet() par un col_select diminue considérablement la charge mémoire, expliquant la réduction du temps d’exécution d’un facteur 7 :
read_parquet("data/FD_MIGCOM_2019.parquet", col_select = c(COMMUNE, IRAN, IPONDI)) |>
filter(COMMUNE == '31555' & IRAN != '1') |>
summarise(i = sum(IPONDI))
# 93151
# 1 s
Pour autant, on n’évite pas la recopie d’une partie du contenu de FD_MIGCOM_2019.parquet (trois colonnes) vers la mémoire de travail de R.
La variante DuckDB est bien plus optimisée : le fichier FD_MIGCOM_2019.parquet est lu et traité en place sans (presque) aucune recopie des données en mémoire :
library(duckdb)
con <- dbConnect(duckdb::duckdb())
dbGetQuery(con, "SELECT sum(IPONDI) FROM 'data/FD_MIGCOM_2019.parquet'
WHERE COMMUNE = '31555' AND IRAN <> '1'")
# 93151
# 150 ms
Cette notion de « zéro-copie » est fondamentale : elle est au cœur du projet Arrow et avant lui de la conception du format Parquet.
Les requêtes compilées sont plus efficaces
Une requête considérée globalement est plus facilement optimisable par un moteur intelligent, qui va chercher le meilleur plan d’exécution. C’est comme cela que les moteurs de bases de données relationnelles fonctionnent, prenant en considération par exemple les clés et les index ajoutés aux tables.
Le chainage proposé par dplyr (ou Pandas dans Python) est toutefois plus agréable à écrire ou à relire qu’une requête SQL. Comment réunir le meilleur des deux mondes ?
C’est possible dans R avec open_dataset() qui plutôt que lire directement le contenu du fichier, se contente d’ouvrir une connexion, prélude à l’écriture d’une chaine d’instructions qui ne sera compilée et exécutée que par l’ordre final collect() :
open_dataset("data/FD_MIGCOM_2019.parquet") |>
filter(COMMUNE == '31555' & IRAN != '1') |>
summarise(i = sum(IPONDI)) |>
collect()
# 93151
# 1 s
Cette écriture conduit le moteur (ici arrow et non plus dplyr) à comprendre qu’il n’a pas besoin de lire toutes les colonnes de la table Parquet. Elle n’est pas tout à fait aussi rapide que le SQL direct dans DuckDB, mais elle s’en approche.
Partitionnez pour simplifier le stockage et les mises à jour
open_dataset() a un autre mérite, celui de permettre d’ouvrir une connexion vers un ensemble partitionné de fichiers physiques décrivant la même table de données.
La base des migrations fait ici 200 Mo, c’est relativement faible. On considère qu’un fichier Parquet peut raisonnablement aller jusqu’à 2 Go. Au-delà, il y a tout intérêt à construire un dataset partitionné.
La base des courses des taxis de New-York représente 40 Go de données couvrant plusieurs années, et elle se décompose en une partition de dizaines de fichiers Parquet, découpés par année et par mois. Ce découpage est logique, il permet par exemple de ne mettre à jour que les nouveaux mois de données fraichement disponibles. La clé de partitionnement correspond également à une clé de filtrage assez naturelle.
R et Arrow arrivent à requêter l’ensemble de ce dataset en moins d’une seconde (DuckDB fait cinq à dix fois mieux).
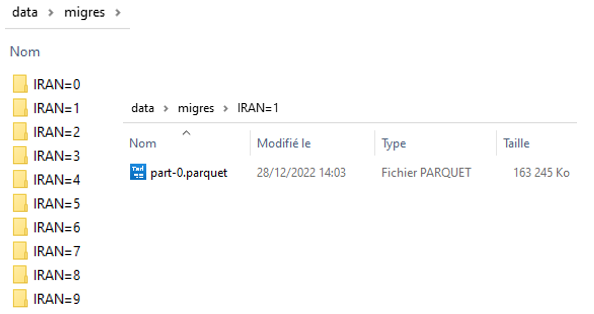
Voici comment constituer un dataset Parquet partitionné à partir de la base plus modeste des migrations résidentielles, avec ici un seul champ de partitionnement :
write_dataset(fread("data/FD_MIGCOM_2019.csv") |> mutate(across(-IPONDI, as.character)),
path = "data/migres",
partitioning = c('IRAN'))
Cela crée une petite arborescence de fichiers Parquet :
Nous pouvons désormais comparer les performances de la même requête, sur l’ensemble partitionné en dix fichiers, ou sur le fichier Parquet unique.
La partition accélère naturellement nettement l’exécution (200 ms contre 1 s) car le filtrage suivant sur IRAN correspond à la clé de partitionnement, il n’est donc pas besoin d’ouvrir le second fichier de la partition :
open_dataset("data/migres", partitioning = c('IRAN')) |>
filter(COMMUNE == '31555' & IRAN != 1) |>
summarise(i = sum(IPONDI)) |>
collect()
# 93151
# 200 ms
open_dataset("data/FD_MIGCOM_2019.parquet") |>
filter(COMMUNE == '31555' & IRAN != '1') |>
summarise(i = sum(IPONDI)) |>
collect()
# 93151
# 1 s
Parquet et DuckDB surpassent les bases de données relationnelles classiques
Je me suis intéressé à cette base de migrations pour conseiller un client peinant à la traiter dans R. Travaillant dans une agence d’urbanisme, il voulait simplement extraire les données pertinentes pour sa métropole. Dans le cas de Toulouse, cela reviendrait à extraire de la base les personnes résidant dans l’EPCI de Toulouse-métropole, ou y ayant résidé l’année précédente.
Je m’appuie pour ce faire sur une table annexe listant les communes de Toulouse Métropole. Il s’agit ensuite d’opérer une double jointure avec la base des migrations, utilisant successivement COMMUNE (code de la commune de résidence) et DCRAN (code de la commune de résidence antérieure).
Grâce à DuckDB, cela s’exécute en 2 secondes, je n’ai même pas eu à me préoccuper d’indexer la table principale. Dans PostgreSQL 15, même après avoir indexé COMMUNE et DCRAN, la requête prend plus de 20 secondes. Ite missa est. DuckDB et Parquet écrasent tout !
library(duckdb)
con = dbConnect(duckdb::duckdb())
dbSendQuery(con, "CREATE TABLE COM_EPCI_TOULOUSE
AS SELECT * FROM read_csv('data/communes_epci_tls.csv',
AUTO_DETECT = TRUE, ALL_VARCHAR = TRUE)")
dbGetQuery(con, "SELECT M.* FROM 'data/FD_MIGCOM_2019.parquet' as M
LEFT JOIN COM_EPCI_TOULOUSE as C1 ON M.COMMUNE = C1.CODGEO
LEFT JOIN COM_EPCI_TOULOUSE as C2 ON M.DCRAN = C2.CODGEO
WHERE C1.CODGEO IS NOT NULL OR C2.CODGEO IS NOT NULL
") |> summarise(i = sum(IPONDI))
# 282961
# 2,5 s
Parquet et Arrow sont deux technologies complémentaires
Cloudera est l’une des entreprises conceptrices originelles de Parquet, en 2013, avec Twitter et Google. Quand Wes McKinney la rejoint en 2014, lui qui a créé la célèbre librairie Pandas pour Python (équivalent de R/Tidyverse), il comprend vite qu’il y a là un format d’avenir : un modèle de « dataframe » universel, qui peut encore s’optimiser.
Wes rêve d’un format de données qui soit quasi-identique dans sa représentation physique (stockée ou streamée via les réseaux) à sa représentation en mémoire, qui éviterait toutes ces coûteuses opérations de conversion des différents formats textes ou « propriétaires » vers les bits que manipulent les processeurs. Le pire exemple est naturellement celui du CSV, où les nombres sont d’abord stockés comme des chaines de caractères, qu’il faut décoder (« désérialiser »). Avec ce format idéal auquel le projet Apache Arrow donne forme à partir de 2016, les processeurs pourront déplacer des pointeurs vers des sections de bits de données, sans jamais les recopier.
Si Parquet, format binaire « streamable » (découpable en petits morceaux autonomes) orienté colonnes, s’approche de cet idéal, il impose tout de même une forme de décodage avant d’être porté en mémoire, par exemple parce qu’il compresse les données. A contrario, un fichier physique constitué à partir d’un format Arrow prend beaucoup plus de place car il n’est pas compressé.
Parquet a le mérite d’exister et d’être déjà beaucoup utilisé, il est optimisé pour l’archivage et le partitionnement, Arrow pour les traitements, les accès concurrents et les systèmes très distribués.
Wes McKinney a su motiver de très bons programmeurs au sein du projet Apache Arrow pour bâtir à la fois une spécification de format et des librairies partagées, dont une interface très performante entre Parquet et Arrow. Nous voyons – nous humains – des fichiers Parquets, les moteurs analytiques et les réseaux travaillent à partir de leur conversion en structures Arrow.
Dans le même ordre d’idée, plutôt que chacun dans son coin implémente un module de lecture de fichiers CSV, l’effort est désormais centralisé au sein du projet Arrow. R, Python, Rust, Julia, Java et bien d’autres réutilisent les librairies C++ du projet Arrow. Il en existe même un portage pour JavaScript en Web-Assembly : nos navigateurs savent désormais lire des fichiers Arrow ou Parquet (cf. les librairies Arrow.js, Arquero ou duckdb-wasm).
Ainsi, à rebours de la logique intégrée des systèmes de bases de données, il est aujourd’hui possible de rendre indépendants – sans sacrifier la performance – les sources de données et les moteurs analytiques, les uns et les autres pouvant se déployer dans n’importe quel environnement, portable ou distribué.
GéoParquet pourrait renouveler le stockage des données géographiques tabulaires
Le cahier des charges de Parquet prévoyait la possibilité de décrire des colonnes stockant des structures complexes, imbriquées, organisées en listes. Parquet est donc tout à fait capable de modéliser des données spatiales, qui complètent typiquement une table de données classique par un champ géométrique.
À la clé, tous les avantages déjà évoqués : stockage réduit, données volumineuses possiblement partitionables, traitements accélérés, nouveau standard plus facilement acceptable par l’industrie, réduisant l’écart entre l’exotisme des formats SIG et les formats de données statistiques plus traditionnels.
Géoparquet permettra de gérer plusieurs systèmes de référence géographique dans le même dataset, voire plusieurs colonnes de géométrie.
Le projet GeoParquet est déjà bien avancé et le format est d’ores et déjà utilisable. Vous pouvez générer des fichiers GeoParquet avec R ou Python, et les ouvrir, grâce à l’intégration GeoParquet dans GDAL, dans la dernière version de QGIS (3.28).
Voici un exemple à partir d’un fichier historique des cultures en Ariège, obtenu au format geopackage. La conversion en GeoParquet aboutit à un fichier deux fois plus petit, de contenu identique. L’équivalent au format Esri shape produirait un ensemble de fichiers de plus de 500 Mo, de taille quasiment 10 fois supérieure.
Les trois versions s’ouvrent dans R ou dans QGIS avec la même rapidité.
library(sf)
library(sfarrow)
# https://entrepot.recherche.data.gouv.fr/file.xhtml?persistentId=doi:10.57745/UTKSVA&version=4.2
# le gpkg pèse 110 Mo
# l'équivalent esri shape 540 Mo
gpkg_file = "data/filiation_20_07.gpkg"
# liste des couches de ce geopackage : 1 seule couche
st_layers(gpkg_file)
read_sf(gpkg_file) |> st_write_parquet("data/filiation_20_07_d09.parquet")
# le geoParquet généré pèse 60 Mo
Pour résumer
Parquet est un standard ouvert particulièrement bien adapté pour stocker des données volumineuses, et traiter des fichiers avec beaucoup de colonnes, ou comprenant des nomenclatures.
Sa structure astucieusement croisée et documentée en colonnes et en groupes de lignes exploite à merveille les capacités des processeurs modernes : parallélisation, vectorisation, mise en cache. Elle est aussi compatible avec une organisation partitionnée ou une distribution « streamée » des données.
Comme Arrow, Parquet épouse le principe de localité : rapprocher les process des données, les lire là où elles se trouvent, plutôt que recopier les données dans des espaces de traitement spécialisés. C’est l’objectif du « zéro-copie » : il permet de travailler avec des données plus volumineuses que la mémoire disponible et de dépasser ce goulet d’étranglement classique, bien connu des praticiens de R ou Python.
GéoParquet est en passe de résoudre le casse-tête de l’hétérogénéité des formats SIG, de leur apporter de nouveaux gains de performance et de substantielles économies de stockage.
Un des formats majeurs de la boite à outils Arrow, Parquet est la face émergée d’un nouvel écosystème décloisonnant les données et les process qui les traitent, complémentaire des bases de données relationnelles traditionnelles.
Si la plupart des outils d’analyse de données lisent désormais les fichiers Parquet, le nouveau moteur portable DuckDB est tout spécialement optimisé pour en tirer le meilleur parti. Il démontre des performances extraordinaires, qui ne cessent de croitre, tirées par la créativité et l’enthousiasme d’une belle communauté de développeurs open-source.
Pour aller plus loin
Présentation du format
- Apache Parquet pour le stockage de données volumineuses
- What is the Parquet File Format?
- What Is Apache Parquet?
- Parquet file format
Différences Arrow / Parquet
- Difference between Apache parquet and arrow
- https://arrow.apache.org/blog/2022/10/05/arrow-parquet-encoding-part-1/
- The Columnar Roadmap: Apache Parquet and Apache Arrow
Pour jouer avec Parquet
- Tad: A better way to view & analyze data
- Online, Privacy-Focused Parquet File Viewer
- Dbeaver: Universal Database Tool
- How to set up DBeaver SQL IDE for DuckDB
- DuckDB redonne une belle jeunesse au langage SQL
- Package R Parquetize
Le projet Arrow
Attention il y a une grosse bêtise d’écrite un peu plus haut indiquant qu’en python il faudrait charger en ram l’intégralité d’un csv pour le lire.
C’est faux, en utilisant csv.DictReader et en lisant ligne par ligne, absolument rien n’oblige à charger en ram l’intégralité d’un csv (et on peut même lire directement une version zippée du fichier si l’on souhaite qu’il prenne moins de place également sur le disque dur)
Ce n’est pas ce que je dis, ou que j’ai en tête : dans R (que je connais mieux) par exemple, on ne peut pas requêter directement un fichier CSV en SQL (ou dplyr), et surtout pas intelligemment, il faut en lire toute les lignes, les parser à partir du délimiteur, avant de pouvoir éventuellement les filtrer, etc. Avec Parquet (ou Arrow), on sait plus rapidement ce qu’il faut lire, pour ne regarder que les colonnes pertinentes, et bien souvent que les lignes pertinentes.
Merci super synthèse!
Retour de ping : Best Of Tech #60 - Atol Open Blog
Bonjour,
Merci pour cette information et cette synthèse complète (avec même des exemples wow !)
Mais ce document date d’il y a quasi un an, est-ce qu’une mise à jour est prévue, où en est ce projet ?
Bonjour, et merci pour votre avis. Une suite est proposée sur ce même blog : https://www.icem7.fr/outils/3-explorations-bluffantes-avec-duckdb-1-interroger-des-fichiers-distants/
D’une façon générale, le format parquet se propage gentiment, notamment à l’Insee.
Bonjour,
Je confirme que le format se propage à l’Insee. Il est même devenu le format recommandé de tout export de données Insee (il faut encore que l’ensemble des processus concernés soient adaptés à cette orientation).
Et merci pour cette confirmation, c’est une bonne nouvelle.