DuckDB révolutionne notre approche des données. En dépit de sa console austère, fleurant bon l’antique terminal, ce petit programme de moins de 20 Mo butine allègrement les bases les plus retorses, les plus lourdes ; qu’elles se présentent en CSV, (Geo)JSON, parquet ou en SGBD classique.
Vous êtes nombreux déjà à avoir entendu parler de cet ovni, à savoir que DuckDB est véloce, qu’il repose sur ce bon vieux langage SQL. Je veux vous présenter dans cette série de trois articles des possibilités que vous n’imaginez même pas. J’ai dû moi-même, parfois, me secouer la tête et retester soigneusement pour vérifier que je ne me trompais pas.
Commençons dans ce premier article par le travail direct avec des bases de données distantes, compressées, en open data sur Internet. Je prendrai deux exemples.
A - La base Insee du recensement de la population 2020
Premier exemple, l’Insee, l’institut statistique français, vient de mettre en ligne la base détaillée du recensement, niveau individus et logements, au format parquet. Dans ce format parquet, chaque fichier pèse tout de même 500 Mo. Mais vous n’avez pas besoin de les télécharger pour travailler avec.
Je me pose la question suivante : à Paris, quels sont les arrondissements où la part des ménages ayant plus de 2 voitures est la plus forte ? Inversement on pourra s’intéresser aux arrondissements qui privilégient le ‘sans voiture’.
Je vous livre sans ménagement la requête SQL, le graphique exposant le résultat, et juste après, je vous explique. Pour le moment, retenez que vous pouvez exécuter cette requête vous-même, avec DuckDB, qu’elle consomme 12 Mo de bande passante, et prend en gros 2 secondes pour s’exécuter.
WITH tb1 AS (
SELECT ARM, VOIT, sum(IPONDI/NPERR::int) AS eft,
sum(eft) OVER (PARTITION BY ARM) AS tot,
round(1000 * eft / tot)/10 AS pct
FROM 'https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-individus-localises-au-canton-ou-ville-2020-1/20231023-122841/fd-indcvi-2020.parquet'
WHERE dept = '75' AND NPERR <> 'Z'
GROUP BY GROUPING SETS((ARM, VOIT),(VOIT))
),
tb2 AS (
PIVOT_WIDER (SELECT arm, voit, pct FROM tb1) ON VOIT USING first(pct)
)
SELECT CASE WHEN ARM = '75001' THEN '1er' WHEN ARM IS NULL THEN 'Paris'
ELSE CONCAT(RIGHT(ARM,2)::int, 'e') END AS 'Arrondt',
"0" AS 'pas de voiture', "1" AS '1 voiture', "2" AS '2 voitures',
"2" + "3" AS '2 voitures ou +', "3" AS '3 voitures ou +' FROM tb2
ORDER BY (Arrondt = 'Paris')::int, "2 voitures ou +" DESC ;
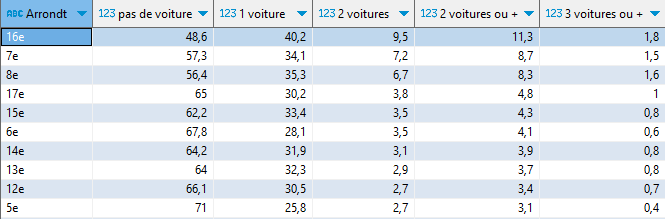
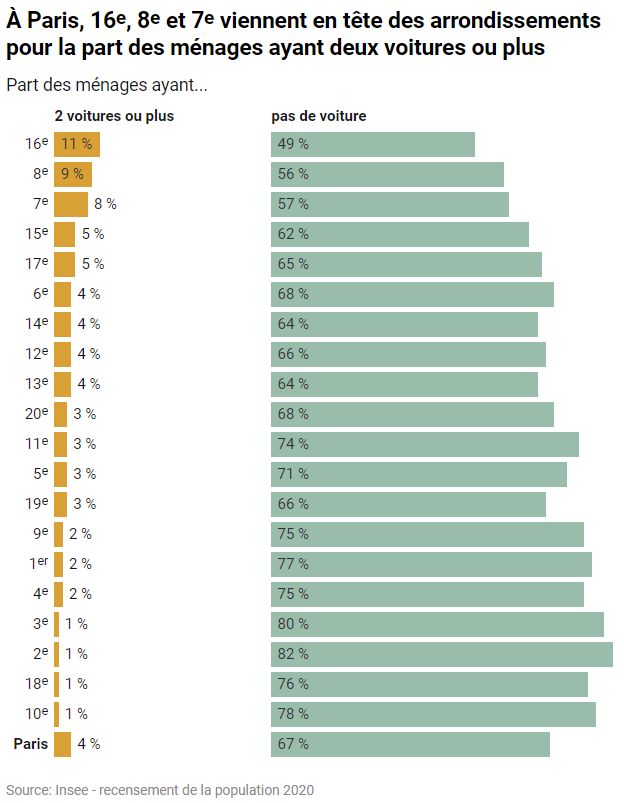
À l’opposé, les 2e et 3e arrondissements sont ceux où la part de ménages sans voiture est la plus élevée (huit ménages sur dix).
Décortiquons
Comme l’URL de la base est longue, pour simplifier mon exposé, je crée d’abord une vue SQL, qui n’est qu’un alias vers ce fichier distant :
CREATE OR REPLACE VIEW fd_indcvi_2020 AS
FROM 'https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-individus-localises-au-canton-ou-ville-2020-1/20231023-122841/fd-indcvi-2020.parquet';
Ne vous étonnez pas de l’absence d’un SELECT * avant le FROM, DuckDB permet de s’en passer – et c’est bien pratique – si l’on veut lire toutes les colonnes de la table.
J’utilise DuckDB soit en lançant le petit exécutable DuckDB.exe, soit à l’intérieur de DBeaver, un environnement gratuit de connexion à de multiples sources de données. DBeaver me permet de gérer de vrais scripts, de les documenter pour les retrouver plus tard. L’affichage et l’export des résultats (en CSV par exemple, ou vers le presse-papier) sont aussi plus sympas.
Une première commande simple nous donne une info minimale, la liste des colonnes et leur type :
DESCRIBE FROM fd_indcvi_2020 ;
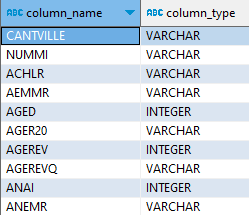
Elle est quasi instantanée (200 ms), et j’ai mis du temps à comprendre ce qui se passait. J’analyse tout de même la structure d’un fichier de 500 Mo, sur data.gouv.fr , et je ne l’ai pas téléchargé. Comment diantre est-il possible d’avoir une info de structure aussi vite ?
Cela tient à deux facteurs :
- Le format parquet stocke dans son en-tête des métadonnées, par exemple la liste des colonnes et leur type ;
- DuckDB envoie un requête HTTP particulière, de type « range-request », qui demande à data.gouv.fr de ne lui servir qu’une petite plage de bytes, une mini-tranche du fichier parquet. Seuls 700 bytes ont transité par le réseau pour nous livrer la structure de ce fichier parquet.
Je repère les variables dont j’aurai besoin : DEPT pour retenir Paris, ARM pour les n° d’arrondissements, VOIT pour caractériser les personnes selon le nombre de voitures du ménage, IPONDI pour calculer un effectif, NPPER pour prendre en compte le nombre de personnes dans le ménage. La documentation du fichier m’offre toute la compréhension nécessaire.
Voici un comptage de ménages, selon leur nombre de voitures, par arrondissement parisien :
SELECT ARM, VOIT,
round(sum(IPONDI/NPERR::int)) AS eft
FROM fd_indcvi_2020
WHERE dept = '75' AND NPERR <> 'Z'
GROUP BY ALL ;
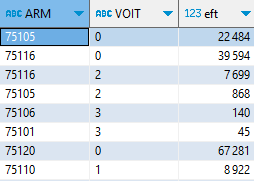
Pour calculer un nombre de ménages, je divise la population par le nombre de personnes dans le ménage. NPPER (tout comme VOIT) n’est pas exactement numérique : 6 veut dire 6 personnes ou plus (3 veut dire 3 voitures ou +) : on s’en accommodera. La modalité Z correspond à des logements « non ordinaires », qu’on laisse ici de côté.
Je produis ensuite un tableau croisé, avec PIVOT_WIDER (qu’on peut aussi écrire, plus simplement, PIVOT) :
WITH tb1 AS (
SELECT ARM, VOIT, round(sum(IPONDI/NPERR::int)) AS eft
FROM fd_indcvi_2020
WHERE dept = '75' AND NPERR <> 'Z'
GROUP BY ARM, VOIT
)
PIVOT_WIDER (FROM tb1) ON VOIT USING first(eft)
ORDER BY ARM ;
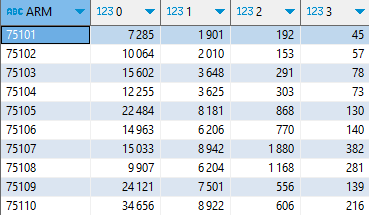
Notez la nouvelle syntaxe que j’utilise pour enchainer deux opérations dans la même requête. Elle est élégante et m’évite de créer une table physique intermédiaire. Ce qui figure dans le WITH () est comme une table temporaire, disponible le temps de la requête.
J’aimerais maintenant calculer le total pour Paris. Je n’ai pour cela qu’à aménager la clause GROUP BY. Le complément GROUPING SETS permet de spécifier ensemble différents niveaux d’agrégation.
WITH tb1 AS (
SELECT ARM, VOIT, round(sum(IPONDI/NPERR::int)) AS eft
FROM fd_indcvi_2020
WHERE dept = '75' AND NPERR <> 'Z'
GROUP BY GROUPING SETS ((ARM, VOIT), (VOIT))
)
PIVOT_WIDER (FROM tb1) ON VOIT USING first(eft)
ORDER BY ARM ;
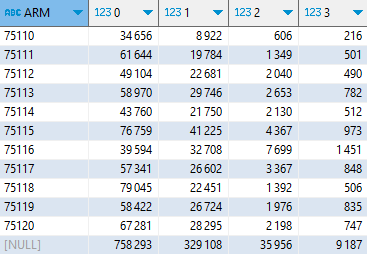
On découvre en bas de tableau la nouvelle ligne ajoutée. On pourra plus tard remplacer ce disgracieux NULL par la mention ‘Paris’.
Maintenant, ce que je voudrais pour répondre à ma question initiale, c’est calculer des pourcentages, pour chaque arrondissement : % de ménages du 12e qui ont 0 voiture, plus de 2 voitures, etc. Pour cela, il me faut le total des ménages pour chaque arrondissement. Il y a plusieurs façons de le faire, plus ou moins manuelles. La plus élégante consiste à utiliser les mots clés OVER et PARTITION.
Revenons à notre premier calcul, avant le PIVOT. Je lui rajoute une ligne, après la première :
SELECT ARM, VOIT, sum(IPONDI) AS eft,
sum(eft) OVER (PARTITION BY ARM) AS tot,
FROM fd_indcvi_2020
WHERE dept = '75' AND NPERR <> 'Z'
GROUP BY GROUPING SETS((ARM, VOIT),(VOIT)) ;
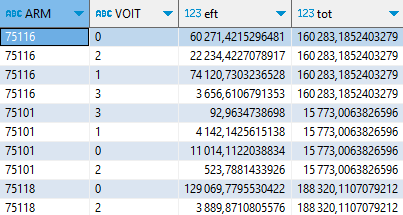
Cette instruction a bien pour effet de calculer un total par arrondissement. PARTITION fonctionne comme un nouveau GROUP BY, mais qui ne change pas le nombre de lignes, il ajoute simplement une colonne calculée. Cette nouvelle instruction relève de la catégorie des « WINDOW functions », très puissantes, dont je ne vais pas décrire toutes les finesses ici.
Une autre des charmantes spécificités du SQL dans DuckDB, c’est que les colonnes calculées sont immédiatement utilisables pour le calcul d’autres nouvelles colonnes.
Ainsi, je peux produire le pourcentage dans le même mouvement :
SELECT ARM, VOIT, sum(IPONDI/NPERR::int) AS eft,
sum(eft) OVER (PARTITION BY ARM) AS tot,
round(1000 * eft / tot) / 10 AS pct
FROM fd_indcvi_2020
WHERE dept = '75' AND NPERR <> 'Z'
GROUP BY GROUPING SETS((ARM, VOIT),(VOIT)) ;
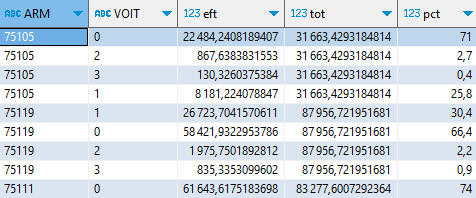
Il ne me reste plus qu’à pivoter et arranger la présentation du résultat final :
WITH tb1 AS (
SELECT ARM, VOIT, sum(IPONDI/NPERR::int) AS eft,
sum(eft) OVER (PARTITION BY ARM) AS tot,
round(1000 * eft / tot)/10 AS pct
FROM fd_indcvi_2020
WHERE dept = '75' AND NPERR <> 'Z'
GROUP BY GROUPING SETS((ARM, VOIT),(VOIT))
),
tb2 AS (
PIVOT_WIDER (SELECT arm, voit, pct FROM tb1) ON VOIT USING first(pct)
)
SELECT CASE WHEN ARM = '75001' THEN '1er' WHEN ARM IS NULL THEN 'Paris'
ELSE CONCAT(RIGHT(ARM,2)::int, 'e') END AS 'Arrondt',
"0" AS 'pas de voiture', "1" AS '1 voiture', "2" AS '2 voitures',
"2" + "3" AS '2 voitures ou +', "3" AS '3 voitures ou +' FROM tb2
ORDER BY (Arrondt = 'Paris')::int, "2 voitures ou +" DESC ;
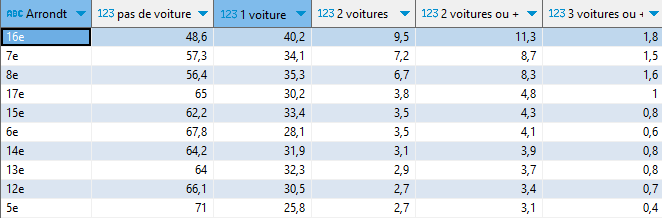
Cette dernière écriture prend 2 secondes et consomme seulement 12 Mo de bande passante. Rappelons-le, elle attaque directement le fichier parquet de 500 Mo en ligne, que je n’ai pas téléchargé au préalable.
Parquet organise l’information par groupe de lignes et par colonne, je n’ai lu via des range-requests que les colonnes dont j’avais besoin pour le calcul, et uniquement pour les lignes correspondant à Paris.
B - Les faits de délinquance du ministère de l’Intérieur
Intéressons-nous maintenant à la base statistique communale de la délinquance enregistrée par la police et la gendarmerie nationales.
Il ne s’agit pas – encore – de fichiers parquet, mais de CSV compressés (csv.gz). Pas de problème, DuckDB peut les lire directement. En revanche, les range-requests ne sont pas aussi puissantes qu’avec Parquet : il faudra lire tout le fichier (39 Mo) avant de pouvoir en tirer parti.
Je crée comme tout à l’heure une vue pour simplifier les écritures. En réalité, cette vue analyse déjà tout le fichier pour deviner la structure les colonnes (j’ai mesuré 1 seconde d’attente).
CREATE OR REPLACE VIEW faits_delinq AS
FROM 'https://static.data.gouv.fr/resources/bases-statistiques-communale-et-departementale-de-la-delinquance-enregistree-par-la-police-et-la-gendarmerie-nationales/20230719-080535/donnee-data.gouv-2022-geographie2023-produit-le2023-07-17.csv.gz';
-- ou, avec un lien stable sur data.gouv.fr
-- FROM read_csv('https://www.data.gouv.fr/fr/datasets/r/8debb975-02da-4bfc-808f-42d18ad76d0b');
Ce qui fait qu’un DESCRIBE devient instantané :
DESCRIBE FROM faits_delinq ;
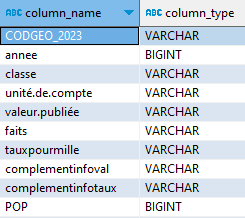
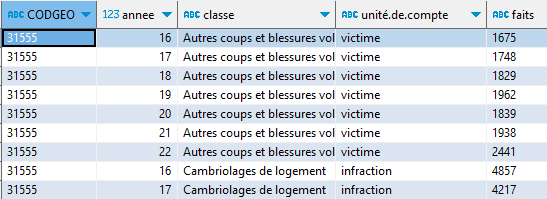
CODGEO_2023 est certainement le code commune, je me fabrique un aperçu de la table pour ma ville, Toulouse :
FROM faits_delinq WHERE CODGEO_2023 = '31555' LIMIT 10 ;
Les informations utiles sont : l’année (qu’il faudra arranger), la classe et le nombre de faits. On peut noter que l’unité des faits dépend de la classe d’infraction : victimes ou voitures par exemple.
Avec un PIVOT, la présentation devient plus claire, et distingue en colonnes une quinzaine de classes de faits de délinquance.
WITH faits_tls AS (
SELECT concat('20', annee) AS an, classe, faits,
FROM faits_delinq
WHERE CODGEO_2023 = '31555'
ORDER BY an, classe
)
PIVOT_WIDER faits_tls ON classe USING first(faits)
ORDER BY an ;
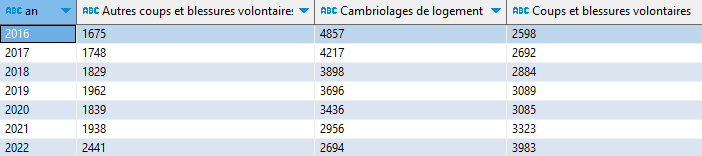
Pour simplifier et construire un graphique, je vais m’en tenir aux seules classes dont le nombre de faits, en fin de période (2022), dépasse les 2 500. Une petite ligne additionnelle, utilisant la puissance des « WINDOW functions », me permet de calculer cette valeur terminale et de filtrer les classes que je veux retenir.
QUALIFY joue le rôle d’un WHERE, et arg_max() – encore une superbe petite fonction – cible le nombre de faits là où an est maximal (donc 2022) :
WITH faits_tls AS (
SELECT concat('20', annee) AS an, classe, faits,
FROM faits_delinq
WHERE CODGEO_2023 = '31555'
QUALIFY arg_max(faits, an) OVER (PARTITION BY classe) > 2500
ORDER BY an,classe
)
PIVOT_WIDER faits_tls ON classe USING first(faits)
ORDER BY an ;
Avec un copier-coller du résultat, je peux produire, avec Datawrapper, cet éclairant graphique :
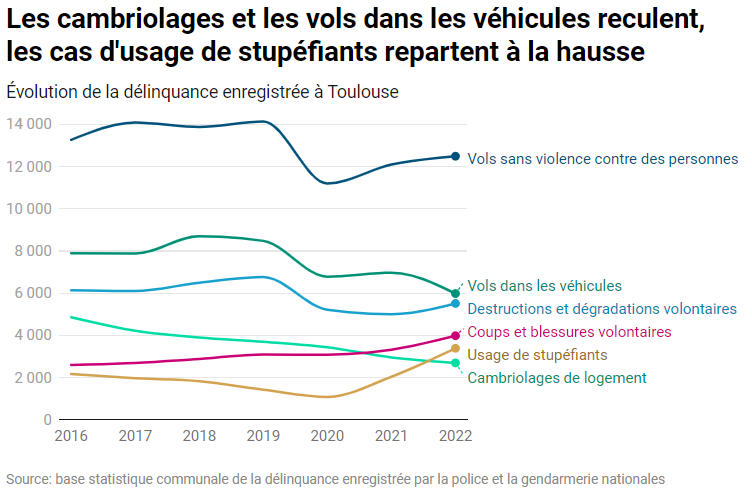
J’ai donc montré avec ces deux exemples comment interroger directement des bases distantes avec DuckDB, et avec beaucoup de souplesse et d’élégance.
J’espère aussi avoir convaincu un peu plus de diffuseurs de bases d’utiliser le format Parquet pour mettre à disposition leurs données.
Dans le prochain épisode (2/3), je parlerai d’API web et du format JSON.
Pour en savoir plus
- 3 explorations bluffantes avec DuckDB – Butiner des API JSON (2/3), icem7, 2023
- 3 explorations bluffantes avec DuckDB – Croiser les requêtes spatiales (3/3), icem7, 2023
- Parquet devrait remplacer le format CSV, icem7, 2022
- DuckDB redonne une belle jeunesse au langage SQL, icem7, 2023
- Guide d’utilisation des données du recensement de la population au format Parquet, Antoine Palazzolo, Lino Galiana, Insee, 2023
- Formation DuckDB, icem7
Merci beaucoup, quelle serait la commande R qui permettrait de lire le parquet depuis une URL ?
J’ai testé
arrow::open_dataset(sources = « https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-individus-localises-au-canton-ou-ville-2020-1/20231023-122841/fd-indcvi-2020.parquet »)
tbl(con, read_parquet(file = « https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-individus-localises-au-canton-ou-ville-2020-1/20231023-122841/fd-indcvi-2020.parquet »))
en vain . est-ce possible ?
Merci, normalement, il faudrait faire :
library(duckdb)
con <- dbConnect(duckdb(), dbdir = ":memory:") dbExecute(con, 'install httpfs') dbExecute(con, 'load httpfs') # ou les deux lignes dbExecute(con, 'SET autoinstall_known_extensions=1') dbExecute(con, 'SET autoload_known_extensions=1') # puis res <- dbGetQuery(con, "describe from 'https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-individus-localises-au-canton-ou-ville-2020-1/20231023-122841/fd-indcvi-2020.parquet'") Mais sous Windows, sur mon poste, bien que l'extension se soit bien installée, elle ne veut pas se charger... Il semble que pour d'autres cela fonctionne mieux : https://francoismichonneau.net/2023/06/duckdb-r-remote-data/
Quant au package arrow dans R, je ne pense pas qu’il puisse lire directement du parquet en https.
res <- duckdbfs::open_dataset('https://static.data.gouv.fr/resources/recensement-de-la-population-fichiers-detail-individus-localises-au-canton-ou-ville-2020-1/20231023-122841/fd-indcvi-2020.parquet'😉
fait le job 🙂
Excellent, merci ! C’est plus simple en effet quand l’extension permettant d’accéder à des fichiers distants est déjà intégrée dans la distribution. Les versions à venir de duckdb devraient charger automatiquement l’extension spatial également.
Retour de ping : Best Of Tech #60 - Atol Open Blog
Bonjour à tous,
vraiment formidable votre blog, duckDb également. Félicitations pour ce beau travail dont je ne cesse de faire la publicité!
je n’ai pas trouvé ce lien : https://static.data.gouv.fr/resources/bases-statistiques-communale-et-departementale-de-la-delinquance-enregistree-par-la-police-et-la-gendarmerie-nationales/20230719-080535/donnee-data.gouv-2022-geographie2023-produit-le2023-07-17.csv.gz
Très bonne journée
Philippe
Bojour Philippe, et merci pour le soutien.
Les liens sur data.gouv.fr évoluent avec le temps. Essayez ceci, avec une URL dite stable, mais moins descriptive, puisqu’elle masque l’extension csv.gz du fichier :
CREATE OR REPLACE VIEW faits_delinq AS
FROM read_csv(‘https://www.data.gouv.fr/fr/datasets/r/8debb975-02da-4bfc-808f-42d18ad76d0b’);