DuckDB saurait-il rivaliser avec JavaScript pour exploiter des données JSON ? Ce n’est pas le terrain sur lequel j’attendais ce moteur SQL. Quelle ne fut pas ma surprise, pourtant, de le voir se jouer des imbrications les plus retorses, des modèles de données les plus échevelés, auxquels JSON accorde volontiers son flexible habillage.
Après le premier épisode consacré aux formats Parquet et CSV dans DuckDB, voici donc à nouveau deux exemples concrets de jeux avec des données formattées en JSON.
A - API recherche d'entreprises : celles autour de chez moi, quelles sont-elles ?
C’est en explorant les belles ressources du portail api.gouv.fr que l’idée de cet article a pris forme. De multiples API de données sont désormais proposées de façon ouverte, sans identification : professionnels bio (Agence bio), base adresses (BAN), demandes de valeurs foncières (DVF), annuaire de l’Éducation nationale, annuaire des entreprises…
Je me suis arrêté sur cette dernière source, interrogeable par une API très simple, construite par la Dinum.
Vous pouvez lui poser deux questions :
• quelles infos peux-tu me donner sur une entreprise ? Ex. : icem7, et si je tape icem77 j’aurai tout de même la bonne réponse ;
• quelles sont les entreprises autour d’un point GPS ?
Alors, j’ai voulu regarder les entreprises près de chez moi. Les bureaux d’icem7 jouxtent mon domicile, j’ai donc bien retrouvé ma société et constaté que nous étions cernés par les sociétés civiles immobilières – le quartier est, il est vrai, plutôt résidentiel.
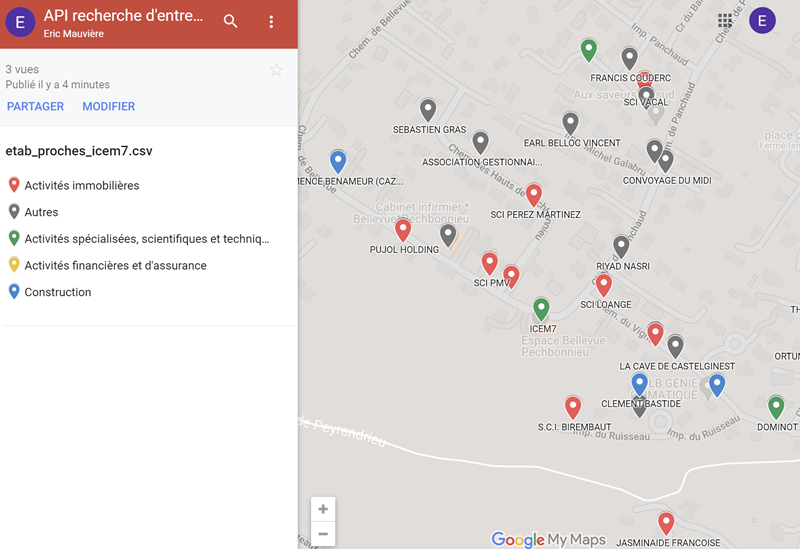
Voyons gentiment comment arriver à un tel résultat, avec DuckDB et un outil web simple.
L’URL suivante construite d’après la doc prend comme paramètres un point GPS (longitude et latitude) et un rayon (en km) ; j’ai choisi 300 m, le rayon maximum est de 50 km.
https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3
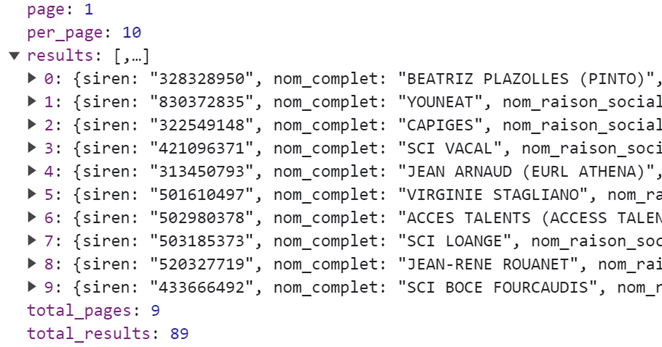
Dans un navigateur (ici Chrome), vous pouvez facilement consulter la réponse dans un affichage confortable et flexible. Quelques données numériques encadrent un « array » JavaScript de results, avec ici 10 entreprises (sur 89 annoncées, dans total_results).
Si je déplie le premier résultat (d’indice 0), se révèle une structure hiérarchique, avec bon nombre de rubriques :
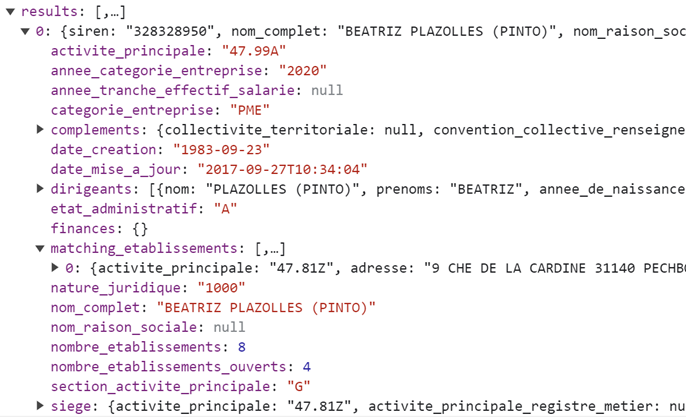
On devine déjà l’intérêt de cette API, pour laquelle la Dinum collationne en temps réel de multiples sources de données : immatriculation et statut juridique, certifications, résultats financiers, siège et établissements. Les entreprises listées ici ont au moins un établissement dans le rayon de ma requête (matching_etablissements).
Que sait lire DuckDB ? Je vais l’utiliser ici dans sa version la plus dépouillée et la plus rapide, l’exécutable de 20 Mo, qui présente les résultats de façon toujours lisible, quelle que soit la largeur de votre écran.
FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3');

Cette simple requête constitue un tableau d’une seule ligne, dont la première colonne reprend results, c’est-à-dire un array (ou liste) de données structurées. Là où JavaScript parle d’array et d’objets, DuckDB évoquera des listes et des structures. Le format Parquet a aussi cette capacité d’accueillir de telles colonnes complexes.
Comment déplier ce tableau en autant de lignes que d’entreprises ?
Découvrons le pouvoir magique (et proprement bluffant, oui) de la fonction unnest() :
SELECT unnest(results, recursive := true)
FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3');
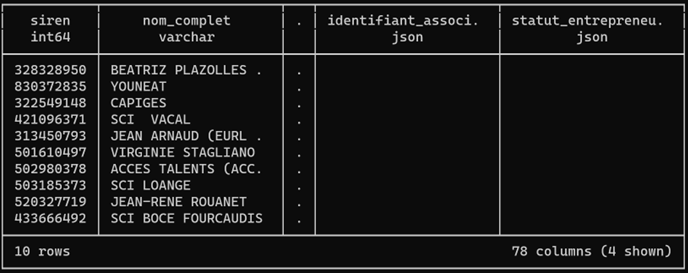
Avec le paramètre recursive := true, unnest() va continuer à déplier les structures cachées dans les colonnes de chaque « result », si bien que le tableau ci-dessus contient désormais 10 lignes et 78 colonnes, autant de pépites d’information sur chaque entreprise.
Affichons-en quelques-unes en clair ; je vais réduire mon champ géographique à 10 m autour de chez moi :
SELECT unnest(results, recursive := true)
FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.01');

Et en effet, je retrouve bien icem7, et même ma précédente entreprise, dont icem7 a pris la suite. Emc3 n’existe plus à cette adresse, l’API renvoie, je le découvre, des entreprises dont le statut administratif a pu évoluer.
Je vais donc affiner mes requêtes ultérieures en demandant à voir, près de chez moi, les seuls établissements actifs :
FROM (
SELECT unnest(results, recursive := true)
FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.01')
)
WHERE list_filter(matching_etablissements,
d -> d. etat_administratif = 'A').len() >= 1 ;
Avec list_filter(), je vous laisse goûter à l’une des nombreuses fonctions de manipulations de listes, qui donnent à DuckDB toute facilité pour explorer des structures imbriquées à la JSON.
Il reste plusieurs colonnes de type liste que unnest() n’a opportunément pas dépliées, car cela aurait encore multiplié le nombre de lignes.
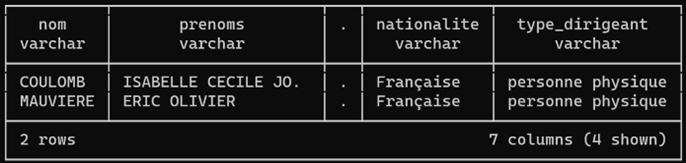
Déplions manuellement la colonne dirigeants, ce qui fait apparaitre une sous-table, où je me reconnais avec mon associée. On y trouve des infos étonnamment personnelles comme l’identité, la nationalité et même la date de naissance (que je ne dévoile pas ici, par galanterie) !
WITH tb1 AS (
SELECT unnest(results, recursive := true)
FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.01')
)
SELECT unnest(dirigeants, recursive := true) FROM tb1
WHERE list_filter(matching_etablissements,
d -> d. etat_administratif = 'A').len() >= 1 ;
Sur les 78 colonnes de la table dépliée, je vais donc choisir quelques infos parmi les plus parlantes, afin de localiser ces entreprises et d’en savoir plus sur ce qu’elles font et qui les dirige. Je peux identifier des certifiés « bio » (producteurs ou revendeurs / préparateurs), des organismes de formation, par exemple ceux certifiés Qualiopi comme icem7.
Par commodité, je m’en tiens au seul premier établissement près de chez moi d’une même entreprise. DuckDB utilise des indices qui commencent par 1 (et non 0 comme dans JavaScript).
SELECT siret, nom_complet, activite_principale, dirigeants,
matching_etablissements[1].longitude::float AS lon,
matching_etablissements[1].latitude::float AS lat, est_qualiopi
FROM (
SELECT unnest(results, recursive := true)
FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3')
)
WHERE list_filter(matching_etablissements,
d -> d. etat_administratif = 'A').len() >= 1 ;
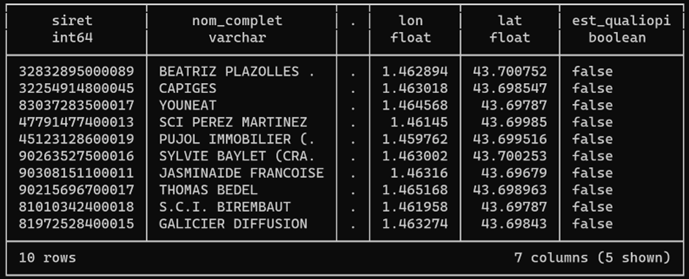
Avec ce premier résultat, je pourrais déjà cartographier ces entreprises et produire une analyse coloriée par code activité (NAF).
Dépasser les contraintes de l'API
Bien sûr, le problème est que je n’ai reçu d’infos que sur 10 entreprises. Voyons comment relever le curseur. La doc de l’API indique que je peux pousser jusqu’à 25 entreprises par appel, et lancer 7 appels par seconde.
Pour avoir les 89 établissements à 300 m de chez moi, je m’attends donc à m’y reprendre à plusieurs fois.
SELECT total_results, total_pages
FROM read_json_auto('https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25');

Avec le paramètre per_page=25, l’API me renvoie désormais une première « page » de 25 résultats, et me précise le nombre de pages nécessaires (4). Pour avoir la page 2, je dois ajouter à l’URL un paramètre &page=2.
DuckDB permet commodément de charger dans le même mouvement toute une collection d’URL :
SELECT unnest(results, recursive := true)
FROM read_json_auto([
'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25',
'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25&page=2',
'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25&page=3',
'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25&page=4'
]) ;
Mais une telle écriture reste bien lourde. Il y a plus élégant, plus « vectoriel » :
SELECT unnest(results, recursive := true)
FROM read_json_auto(
list_transform(generate_series(1, 4),
n -> 'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25&page=' || n)
) ;
generate_series(1, 4) produit un vecteur [1,2,3,4], lequel se voit transformer avec list_transform() en un vecteur d’URL.
Je suis donc en mesure de récupérer en une seule requête tous mes voisins entrepreneurs, et pour ne pas solliciter l’API à chaque raffinement de mes écritures, je vais stocker ce premier résultat dans une table.
CREATE OR replace TABLE etab_proches_icem7 AS FROM (
SELECT unnest(results, recursive := true)
FROM read_json_auto(
list_transform( generate_series(1, 4),
n -> 'https://recherche-entreprises.api.gouv.fr/near_point?lat=43.69875&long=1.46158&radius=0.3&per_page=25&page=' || n)
)
)
WHERE list_filter(matching_etablissements,
d -> d. etat_administratif = 'A').len() >= 1 ;
Voici un aperçu de cette table de 89 établissements, liste que j’ai triée pour montrer en premier les organismes de formation certifiés Qualiopi ; icem7 apparait bien.
SELECT nom_complet, activite_principale,
matching_etablissements[1].longitude::float AS lon, matching_etablissements[1].latitude::float AS lat,
est_organisme_formation, est_qualiopi
FROM etab_proches_icem7
ORDER BY est_organisme_formation DESC, nom_complet ;
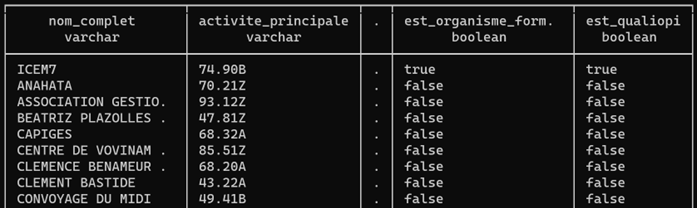
Désormais, je peux cartographier ce résultat à partir d’un export GeoJSON de cette table :
LOAD SPATIAL ;
COPY (
SELECT nom_complet, activite_principale,
ST_Point(matching_etablissements[1].longitude::float,
matching_etablissements[1].latitude::float) AS geometry
FROM etab_proches_icem7
) TO 'C:/.../entr_proches_icem7.json'
WITH (FORMAT GDAL, DRIVER 'GeoJSON') ;
L’export GeoJSON repose sur l’extension SPATIAL, que je charge au préalable (cette procédure devrait prochainement se simplifier dans DuckDB, avec un chargement automatique déclenché dès l’appel d’une fonction spatiale).
La table doit ensuite comprendre une colonne de géométrie (nommée obligatoirement geometry), ici une colonne ponctuelle générée avec la fonction ST_Point().
Je fais glisser le fichier ainsi créé dans l’interface de geojson.io pour découvrir – enfin – cette carte des entreprises près de chez moi – et elles sont nombreuses !
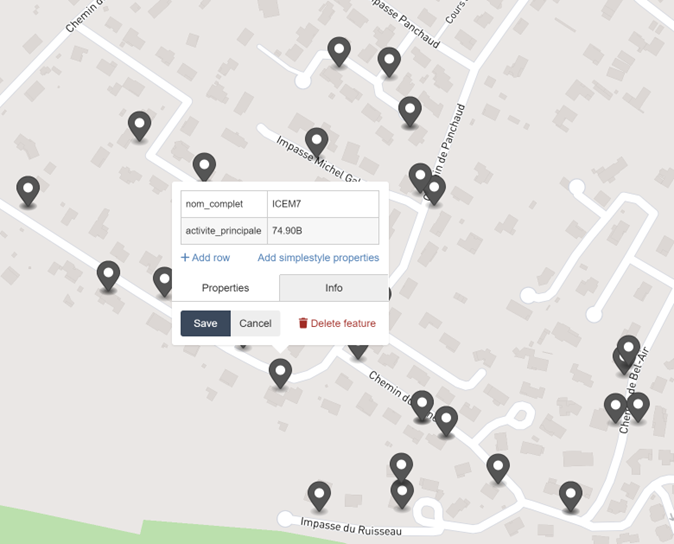
Joindre une nomenclature
Le code activité principale, issu de la NAF, me parle peu, je vais donc chercher des libellés clairs.
Grâce à SQL, le pouvoir des jointures, et la capacité de DuckDB à piocher directement sur le web, je récupère, par une table de passage constituée par mes soins au format parquet, les différents niveaux d’agrégation de la NAF et leurs dénominations.
SELECT nom_complet, activite_principale,
ST_Point(matching_etablissements[1].longitude::float,
matching_etablissements[1].latitude::float) AS geometry,
n.LIB_NIV5,n.LIB_NIV1
FROM etab_proches_icem7
LEFT JOIN 'https://static.data.gouv.fr/resources/naf-1/20231123-121750/nafr2.parquet' n
ON etab_proches_icem7.activite_principale = n.NIV5 ;
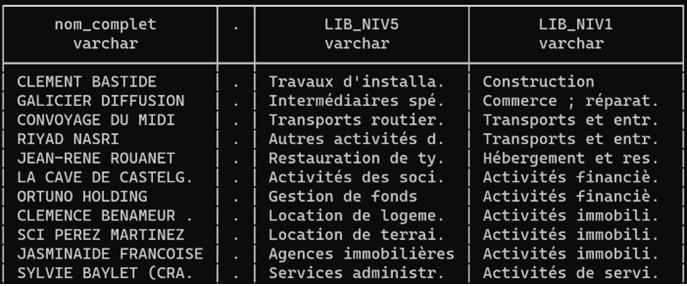
Cartographier selon l'activité principale
Pour produire une cartographie plus analytique, avec des punaises coloriées selon l’activité, j’utilise le service MyMaps de Google, seul outil en ligne que j’aie pu identifier pour ce faire et afficher en arrière-plan une couche de rues.
Maps ne lit pas de GeoJSON mais accepte le CSV, pourvu qu’on y insère les deux colonnes longitude et latitude (nommées comme on veut).
COPY (
SELECT nom_complet, activite_principale,
matching_etablissements[1].longitude AS lon,
matching_etablissements[1].latitude AS lat,
n.LIB_NIV5,n.LIB_NIV1
FROM etab_proches_icem7
LEFT JOIN 'https://static.data.gouv.fr/resources/naf-1/20231123-121750/nafr2.parquet' n
ON etab_proches_icem7.activite_principale = n.NIV5
) TO 'C:/.../etab_proches_icem7.csv' ;
Comme il me reste, même au niveau le plus agrégé de la NAF, beaucoup de modalités différentes, je termine en créant un code activité simplifié, avec une catégorie « Autres » regroupant les effectifs les plus faibles :
COPY (
WITH tb1 AS (
SELECT nom_complet, activite_principale,
matching_etablissements[1].longitude AS lon,
matching_etablissements[1].latitude AS lat,
n.LIB_NIV5,n.LIB_NIV1,
count(*) OVER (PARTITION BY LIB_NIV1) AS eft_naf
FROM etab_proches_icem7
LEFT JOIN 'https://static.data.gouv.fr/resources/naf-1/20231123-121750/nafr2.parquet' n
ON etab_proches_icem7.activite_principale = n.NIV5
)
SELECT CASE WHEN eft_naf >= 3 THEN LIB_NIV1 ELSE 'Autres' END
AS activite, *
FROM tb1
) TO 'C:/.../etab_proches_icem7.csv' ;
Et voici une carte interactive, dont vous pouvez déplier la légende (bouton en haut à gauche) ou cliquer les punaises :
B - DataTourisme et le hackaviz DataGrandEst
Mon second exemple sera plus concis, et il a surtout servi à résoudre un problème concret. Mon collègue Alain Roan, qui prépare le Hackaviz du 13 décembre 2023 de DataGrandEst, s’est déclaré lui-même proprement « bluffé » par l’agilité de DuckDB.
Le concours s’appuie sur des données touristiques ; il s’agit de mettre en regard des nuitées et des points d’intérêt (POI) touristiques, c’est-à-dire de tenter d’expliquer la venue des touristes par l’existence de ressources attractives : monuments, spectacles, itinéraires, etc.
Alain et l’agence régionale du tourisme voulaient constituer un fichier de POI avec une double localisation longitude/latitude et code commune Insee. Selon les sources, ils disposaient soit de l’un, soit de l’autre, mais pas des deux.
Ils le savaient, la réponse se trouve dans le portail DataTourisme. Il s’agit d’une superbe initiative, formalisée en 2017, rassemblant en temps réel toutes les sources de données disponibles. Toutefois, son « API web moderne » évoque plutôt les années 1980, époque regrettée des programmes lancés « en batch » sur « grosse machine ». Comme quand j’ai commencé à l’Insee, il faut attendre le lendemain pour disposer des résultats d’une demande d’extraction. Les « flux » ainsi mis à disposition sont d’une fluidité toute relative, celle d’une grosse goutte se détachant toutes les 24 heures.
Plus enthousiasmant encore, la requête en partie décrite dans l’image suivante (région Grand Est) conduit à récupérer une archive de plus de 20 000 fichiers JSON :
Ces 21 211 fiches JSON représentent environ 500 Mo de données, qu’il faut décompresser sur son disque dur pour envisager de les exploiter. Elles s’organisent dans une arborescence à deux niveaux. Les noms de fichier sont peu évocateurs et chaque document présente un contenu assez dense.
Voilà un court extrait d’une fiche pour vous donner une petite idée :
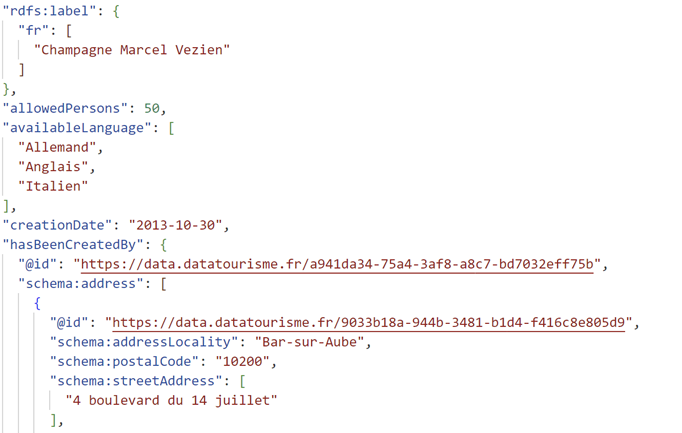
Armé de DuckDB, ma première entreprise fut d’extraire d’une fiche au hasard les variables essentielles pour le hackaviz. Les noms de champ sont un peu pénibles à manier, mais le bonheur de toucher du doigt l’univers enchanté des « ontologies » et du « web sémantique » l’emporte sur le désagrément d’avoir à multiplier les quotes et les crochets :
SELECT
isLocatedAt[1]['schema:address'][1]['hasAddressCity']['insee'] AS code_com,
"rdfs:label"['fr'][1] AS label,
array_to_string("@type", ',') AS types,
array_to_string(isLocatedAt[1]['schema:address'][1]['schema:streetAddress'], ' ') AS streetAddress,
isLocatedAt[1]['schema:address'][1]['schema:postalCode'] AS postalCode,
isLocatedAt[1]['schema:address'][1]['schema:addressLocality'] AS addressLocality,
isLocatedAt[1]['schema:geo']['schema:latitude']::float AS latitude,
isLocatedAt[1]['schema:geo']['schema:longitude']::float AS longitude
FROM read_json_auto('C:\...\objects\2\23\3-23a1b563-5c8c-32e0-b0fc-e0fcbb077b29.json');
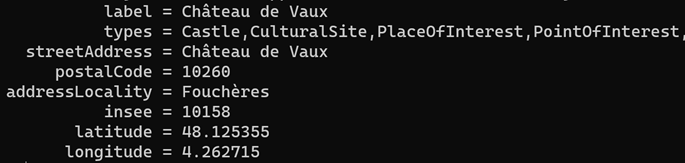
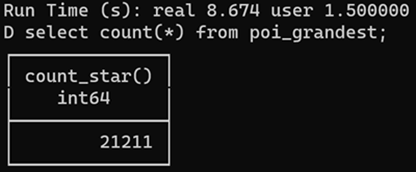
Et voici l’apparition du dernier effet bluffant DuckDB, la lecture en une seule passe et moins de 10 secondes des 21 211 fiches JSON :
CREATE OR replace TABLE poi_grandest AS
SELECT
isLocatedAt[1]['schema:address'][1]['hasAddressCity']['insee'] AS code_com,
"rdfs:label"['fr'][1] AS label,
array_to_string("@type", ',') AS types,
array_to_string(isLocatedAt[1]['schema:address'][1]['schema:streetAddress'], ' ') AS streetAddress,
isLocatedAt[1]['schema:address'][1]['schema:postalCode'] AS postalCode,
isLocatedAt[1]['schema:address'][1]['schema:addressLocality'] AS addressLocality,
isLocatedAt[1]['schema:geo']['schema:latitude']::float AS latitude,
isLocatedAt[1]['schema:geo']['schema:longitude']::float AS longitude
FROM read_json_auto('C:\...\objects\*\*\*.json') ;
L’API DataTourisme est tellement monumentale et raffinée que la plupart des professionnels du tourisme sont incapables de l’utiliser (mais des simplifications sont annoncées pour la fin de l’année). Qu’à cela ne tienne, un marché de développeurs affutés a pu naitre, auxquels les acteurs du tourisme en besoin de données sur mesure commandent des extractions, réalisées en Python, R ou autres langages d’académique facture.
Bienvenue donc au trublion DuckDB, qui sait rendre l’open data véritablement open.
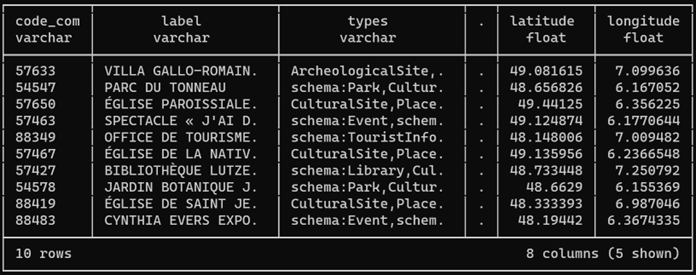
FROM poi_grandest LIMIT 10;
J’ai voulu montrer avec ces deux exemples comment interroger des ressources JSON avec DuckDB, en les manipulant comme des tables. J’ai même pu apparier avec un fichier distant au format Parquet.
L’annuaire des entreprises gagnerait sans doute à être mis à disposition aussi au format parquet. L’API offre de son côté des services spécifiques complémentaires (recherche textuelle, recherche de proximité). Mais le format GeoParquet, dès qu’il aura intégré les index spatiaux, saura rivaliser avec une API par ailleurs contrainte en volume et nombre d’appels.
Dans le prochain épisode (3/3), je parlerai de cartographie, de requêtes spatiales et précisément du format GeoParquet.
Pour en savoir plus
- 3 explorations bluffantes avec DuckDB – Interroger des fichiers distants (1/3), icem7, 2023
- 3 explorations bluffantes avec DuckDB – Croiser les requêtes spatiales (3/3), icem7, 2023
- Parquet devrait remplacer le format CSV, icem7, 2022
- DuckDB redonne une belle jeunesse au langage SQL, icem7, 2023
- Why parquet files are my preferred API for bulk open data, Robin Linacre, 2023
- DuckDB – nested functions
- Annuaire des entreprises
Excellent, d’autant plus que la doc officielle de l’extension Json est superficielle. Merci !
Merci pour votre avis, c’est vrai que le travail sur ce format est moins décrit d’une façon générale.