Nous sommes entourés de données géolocalisées. La séparation données statistiques / données spatiales est bien souvent arbitraire. Mais si elle perdure, c’est parce que les outils SIG (systèmes d’information géographiques) sont lourds à installer et complexes à utiliser.
Avec son extension spatiale, DuckDB met enfin l’analyse géographique à la portée de tou·tes.
Comme dans les deux articles précédents, je vais présenter deux cas concrets, l’un avec les données GTFS de transports en commun dans la métropole toulousaine, l’autre avec la base adresse nationale (BAN).
A - Le standard GTFS pour analyser les transports en commun à Toulouse
Le format GTFS (General Transit Feed Specification) permet aux gestionnaires de transports en commun de mettre à disposition, quotidiennement, des informations détaillées sur leur réseau, les horaires et emplacement des arrêts, le niveau de service. Mis au point par Google en 2005, il s’est imposé comme un standard mondial.
Comme bien d’autres en France et dans le monde, le gestionnaire toulousain Tisséo propose en téléchargement un fichier rafraichi tous les jours, dont la carte ci-dessous restitue l’information purement géographique. Si vous zoomez sur ce composant cliquable (l’IGN propose un fort bel outil web intitulé « Ma carte »), vous verrez apparaître aussi les points d’arrêt.
J’ai construit cette carte interactive avec DuckDB à partir de ce fichier GTFS, gtfs_v2.zip (11 Mo), qui contient sous forme d’archive zippée une collection de fichiers CSV, disposés et structurés selon la norme :
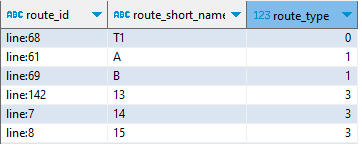
La table routes décrit en bon français des « lignes », de façon purement textuelle, par type (0 = tramway, 1 = métro, 3 = bus, 6 = téléphérique…) : un identifiant unique route_id se distingue du code usuel de la ligne (ex. : ligne A du métro).
La table trips décrit des navettes. Par exemple le bus de la ligne 26 partant à 6 h 03, lundi 18 décembre 2023, de Montberon, terminus Borderouge correspond à une navette identifiée par un trip_id. Une navette a donc une caractéristique symbolique (la ligne), temporelle – horaire et jours – (elle ne circule pas forcément tous les jours à la même fréquence) et spatiale. Elle emprunte un itinéraire physique particulier définit par un shape_id.
La table shapes décrit ces itinéraires et c’est la première table véritablement géographique.
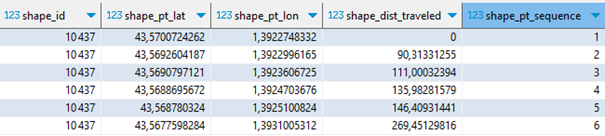
Chaque itinéraire se définit par une suite ordonnée de points GPS (latitude, longitude). Ces points ne correspondent pas aux arrêts, ils sont plus nombreux et définissent les changements d’orientation de l’itinéraire, afin de pouvoir le tracer précisément. Pour une même ligne, il y a généralement un itinéraire aller et un itinéraire retour, qui peuvent légèrement différer.
Les arrêts sont décrits dans la table stops, qui constitue la seconde table géographique. On distingue (via location_type) une zone d’arrêt globale des deux points physiques de l’arrêt, selon la direction désirée.

La table stop_times décrit chaque navette (identifiée par un trip_id) comme une suite d’arrêts situés spatialement et temporellement (stop_id, arrival_time…)
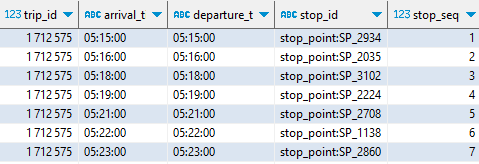
Voilà l’essentiel à retenir de ce riche format. Le site transit.land agrège les principales sources GTFS mondiales et en propose une élégante visualisation.
En avant avec DuckDB spatial
Voyons comment la produire nous-même, avec DuckDB. Je l’utilise ici au sein de l’utilitaire gratuit DBeaver. DBeaver permet de gérer facilement ses scripts SQL (édition, sauvegarde) et de consulter de façon interactive (y compris cartographique) le résultat des requêtes adressées à DuckDB.
Note : depuis le 18 décembre 2023, l’extension SPATIAL de DuckDB est aussi utilisable dans le navigateur.
Chargeons d’abord les tables. Les fichiers du standard GTFS sont généralement mis à disposition sous forme d’une archive .zip. DuckDB ne sait pas lire directement un zip. Deux méthodes sont possibles :
1 – Télécharger et dézipper manuellement sur un disque local, puis, pour chaque table, écrire une instruction comme :
CREATE OR REPLACE TABLE routes AS
FROM read_csv_auto('c:\...\routes.txt') ;
2 – Utiliser un proxy capable de charger le zip et d’extraire à la volée la table désirée, le tout via une simple requête https. C’est possible avec un petit script PHP prenant comme paramètre le nom de la table à extraire et l’URL du zip :
https://icem7.fr/data/proxy_unzip.php?file=routes
&url=https://data.toulouse-metropole.fr/api/explore/v2.1/catalog/datasets/
tisseo-gtfs/files/fc1dda89077cf37e4f7521760e0ef4e9
Utilisons une MACRO pour simplifier les écritures :
CREATE OR REPLACE MACRO get_gtfs(f, cache) AS 'https://icem7.fr/data/proxy_unzip.php?clear_cache=' || cache || '&file=' || f
|| '&url=https://data.toulouse-metropole.fr/api/explore/v2.1/catalog/datasets/
tisseo-gtfs/file/fc1dda89077cf37e4f7521760e0ef4e9';
Le paramètre cache va indiquer au script de conserver le zip sur le serveur proxy le temps d’extraire successivement toutes les tables, ce qui prend 10 secondes.
-- 1er appel forçant le téléchargement du dernier gtfs
CREATE OR REPLACE TABLE routes AS FROM read_csv_auto(get_gtfs('routes', 1)) ;
CREATE OR REPLACE TABLE trips AS FROM read_csv_auto(get_gtfs('trips', 0)) ;
CREATE OR REPLACE TABLE shapes AS FROM read_csv_auto(get_gtfs('shapes', 0)) ;
CREATE OR REPLACE TABLE stops AS FROM read_csv_auto(get_gtfs('stops', 0)) ;
CREATE OR REPLACE TABLE stop_times AS FROM read_csv_auto(get_gtfs('stop_times', 0)) ;
CREATE OR REPLACE TABLE calendar_dates AS FROM
read_csv_auto(get_gtfs('calendar_dates', FALSE),
types=[VARCHAR,DATE,INT], dateformat='%Y%m%d') ;
Pour cartographier le réseau, revenons donc à la table shapes :
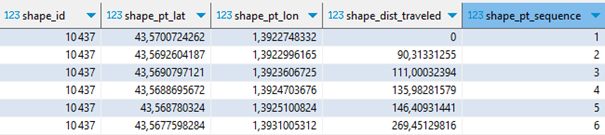
Pour la traduire dans un format spatial, les x lignes décrivant un shape_id particulier doivent être condensées en une seule entité spatiale de type LINESTRING. Autrement dit, la table shapes doit être regroupée par shape_id, chaque enregistrement décrira in fine un itinéraire complet.
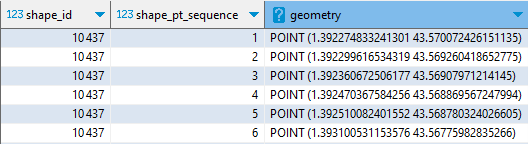
Commençons par créer des entités géométriques de type POINT. Conventionnellement, une telle colonne est dénommée geometry :
LOAD spatial ;
SELECT shape_id, shape_pt_sequence,
ST_Point(shape_pt_lon,shape_pt_lat) AS geometry
FROM shapes ;
Rajoutons une agrégation pour rassembler tous les points d’un tracé (shape_id) en une seule ligne :
WITH shapes_pt_geo AS (
SELECT shape_id, shape_pt_sequence,
ST_Point(shape_pt_lon,shape_pt_lat) AS geometry
FROM shapes
ORDER BY shape_id, shape_pt_sequence
)
SELECT shape_id,
ST_MakeLine(list(geometry)) AS geometry
FROM shapes_pt_geo
GROUP BY ALL ;
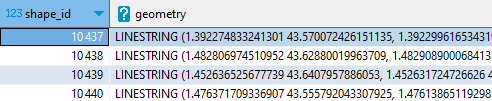
Je n’ai plus que 328 enregistrements (sur les 200 000 de la table shapes).
Et surtout, grâce à la petite manip expliquée ici, je peux visualiser chacun de ces itinéraires, directement dans DBeaver :
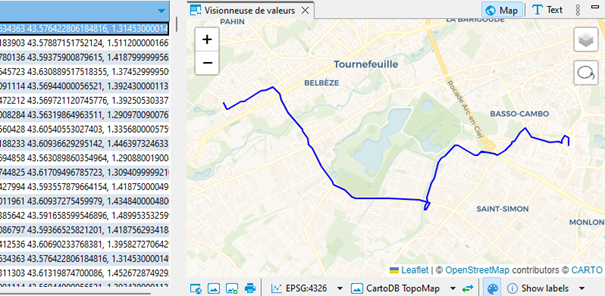
Pour obtenir une table agrémentée du nom des lignes, je vais devoir procéder à deux jointures, ce sont les charmes du format relationnel GTFS :
CREATE OR REPLACE TABLE reseau_gtfs_toulouse_met AS
WITH shapes_pt_geo AS (
SELECT shape_id, shape_pt_sequence, shape_dist_traveled,
ST_Point(shape_pt_lon,shape_pt_lat) AS geometry
FROM shapes
ORDER BY shape_id, shape_pt_sequence
),
shapes_lines_geo AS (
SELECT shape_id, max(shape_dist_traveled)::int AS shape_length,
ST_MakeLine(list(geometry)) AS geometry
FROM shapes_pt_geo
GROUP BY ALL
)
SELECT r.route_id,r.route_short_name,r.route_long_name,r.route_type,
s.shape_id,s.shape_length,s.geometry
FROM shapes_lines_geo s
LEFT JOIN (SELECT DISTINCT route_id, shape_id FROM trips) t
ON s.shape_id = t.shape_id
LEFT JOIN routes r ON r.route_id = t.route_id
ORDER BY r.route_type, r.route_id ;
Et voici dans cet aperçu les deux lignes de métro (A et B), sens aller et retour, deux lignes de bus :
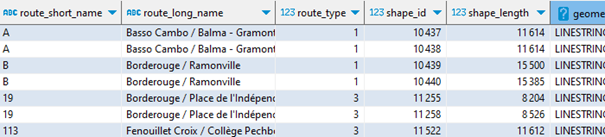
Il ne me reste plus qu’à exporter en GeoJSON pour l’exploiter à ma guise dans une autre application, comme le bien pratique outil web IGN Ma carte.
COPY reseau_gtfs_toulouse_met
TO 'C:/…/reseau_gtfs_toulouse_met.json'
WITH (FORMAT GDAL, DRIVER 'GeoJSON');
J’ai procédé de la même manière avec la table des arrêts, que vous pourrez voir apparaitre en zoomant suffisamment sur la carte.
Simplicité des calculs géométriques
À partir d’un tel fonds de carte et des informations associées, on peut calculer la longueur de chaque itinéraire, le temps de parcours, et donc la vitesse moyenne, pour déterminer les lignes les plus longues, les plus rapides, etc.
Pour chaque shape, nous pouvions lire dans la table shapes d’origine la distance totale parcourue, renseignée par Tisséo. Mais il est possible de la calculer à partir de sa géométrie.
Au préalable, pour obtenir une distance en mètres, il convient de projeter à la volée chaque géométrie vers un référentiel métrique, autrement dit de passer du référentiel « GPS » en longitude/latitude (codé conventionnellement EPSG:4326) au référentiel français Lambert 93 (codé EPSG:2154) :
SELECT route_short_name, route_long_name, shape_length,
ST_length(ST_Transform(geometry,'EPSG:4326','EPSG:2154', true))::int
AS shape_length_calc
FROM reseau_gtfs_toulouse_met
ORDER BY shape_length DESC ;

Comme on peut le constater, le calcul géométrique est très proche, à quelques mètres près, de l’information fournie par Tisséo.
Pour éviter l’empilement des parenthèses, je préfère la syntaxe alternative suivante, plus lisible, inspirée de la programmation fonctionnelle, que DuckDB implémente également :
SELECT route_short_name, route_long_name, shape_length,
geometry.ST_Transform('EPSG:4326','EPSG:2154', true)
.ST_Length()::int
AS shape_length_calc
FROM reseau_gtfs_toulouse_met
ORDER BY shape_length DESC ;
Quels sont les arrêts Tisséo les plus proches de chez moi ?
Autre approche spatiale, et pratique : quels sont les arrêts Tisséo les plus proches de chez moi, et quand sont les prochains départs, et pour où ?
Voici d’abord chez moi :
SELECT ST_Point(1.46158, 43.69875) AS home_location ;
Les arrêts proches de mon domicile (à moins de 700 mètres) se déterminent ainsi :
CREATE OR REPLACE VIEW arrets_proches AS
SELECT ST_Point(stop_lon, stop_lat) AS geometry,
ST_Distance(
ST_Point(stop_lon, stop_lat).ST_Transform('EPSG:4326','EPSG:2154', true),
ST_Point(1.46158, 43.69875).ST_Transform('EPSG:4326','EPSG:2154', true)
)::int AS distance_home,
stop_id, stop_name FROM stops
WHERE distance_home < 700 AND location_type = 0
ORDER BY distance_home ;
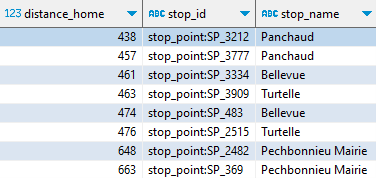
Rappelez-vous, il y a généralement deux arrêts dans la même zone, selon la direction du bus.
Pour faire le lien avec les horaires, le nom de la ligne, et s’en tenir aux horaires valides aujourd’hui à partir de maintenant, engageons une série de jointures et de filtres adaptés (vous n’êtes pas obligés de tout analyser, sauf si vous êtes passionnés par GTFS) :
SELECT route_short_name, route_long_name, stop_name, arrival_time,
trip_headsign, distance_home, trips.trip_id
FROM arrets_proches
JOIN stop_times ON arrets_proches.stop_id = stop_times.stop_id
JOIN trips ON stop_times.trip_id = trips.trip_id
JOIN calendar_dates ON trips.service_id = calendar_dates.service_id
JOIN routes ON routes.route_id = trips.route_id
WHERE arrival_time > localtime AND calendar_dates.date = current_date
ORDER BY arrival_time, distance_home ;
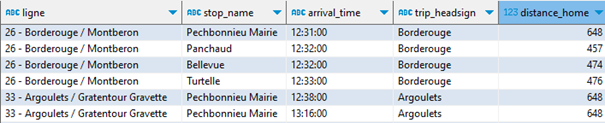
Il reste que la ligne 26 propose plusieurs arrêts près de chez moi ; je souhaite ne retenir que le plus proche.
Il suffira d’un QUALIFY avec une « window function » pour nettoyer le résultat :
WITH trips_proches AS (
SELECT route_short_name || ' - ' || route_long_name AS ligne,
trip_headsign AS terminus,
stop_name, distance_home, arrival_time, trips.trip_id, geometry
FROM arrets_proches
JOIN stop_times ON arrets_proches.stop_id = stop_times.stop_id
JOIN trips ON stop_times.trip_id = trips.trip_id
JOIN calendar_dates ON trips.service_id = calendar_dates.service_id
JOIN routes ON routes.route_id = trips.route_id
WHERE arrival_time > localtime AND calendar_dates.date = current_date
)
SELECT * EXCLUDE(trip_id),
FROM trips_proches
WHERE terminus IN ('Borderouge', 'Argoulets')
QUALIFY rank() over(PARTITION BY trip_id ORDER BY distance_home) = 1
ORDER BY arrival_time, distance_home ;
Et le plus drôle, c’est que ma fille vient de passer me voir et se demandait quand était le prochain bus pour Argoulets. Elle n’en est pas revenue que je lui montre la réponse dans cette étrange interface ! Son appli Tisséo marche très bien aussi…
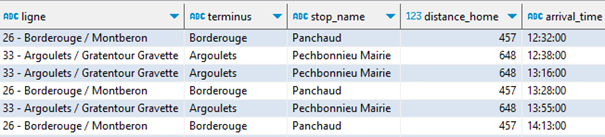
Note : vous pouvez déclencher une requête SQL GTFS via une simple URL.
B – Base adresse nationale (BAN), filaire de voies et GeoParquet
Mon second cas d’étude porte sur des fichiers bien plus volumineux, et me permet d’introduire le format GeoParquet.
Mon précédent logement se trouvait dans une rue limitrophe des communes de Toulouse et de Launaguet. L’état déplorable de la voie s’expliquait, disait-on, par son statut hybride, aucune des deux communes ne voulant s’en occuper à la place de l’autre.
À l’époque, j’aurais pu vouloir rameuter tous les ménages concernés, habitant le long de cette voie limitrophe, ou à proximité immédiate, pour tancer les autorités (mais c’est juste une fable que j’élabore pour l’occasion).
Comment donc compter tous ces voisins ?
Cette voie s’appelle Chemin des Izards, dont une large portion sud commence dans Toulouse, et une autre délimite Toulouse (à gauche) et Launaguet (à droite).
À partir du filaire de voies de Toulouse métropole, je vais récupérer l’ensemble du tracé de la voie. Plutôt que lire un GeoJSON de 20 Mo, j’utilise la version GeoParquet du filaire, que j’ai ainsi réduite à 3 Mo. Comme d’habitude, je lis directement les données sur le web, ici sur data.gouv :
CREATE OR REPLACE TABLE troncons_izards as
SELECT code_insee, street, fromleft, fromright,
geometry
FROM 'https://static.data.gouv.fr/resources/filaire-voiries-toulouse-metropole-format-geoparquet/20231219-050942/filaire-de-voirie-toulouse-met-geo.parquet'
WHERE motdir LIKE 'IZARDS%'
ORDER BY fromleft, fromright ;
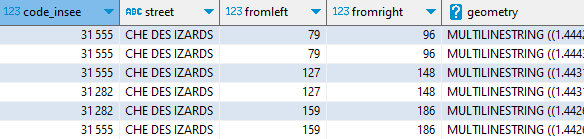
Grace à la lecture ciblée du fichier, les seuls « row-groups » du fichier parquet qui contiennent les données seront chargés et scannés. Ainsi, 1 Mo seulement a transité par le réseau. Ceci est possible parce que j’ai constitué le fichier GeoParquet en le triant sur code_insee et motdir, champs de recherche les plus naturels.
Notez que le champ de géométrie d’un fichier GeoParquet est, selon cette spécification, encodé dans un format spécifique (le WKB). Pour le ramener au format géométrique de DuckDB spatial, il suffit de lui appliquer un ST_GeomFromWKB().
Pour isoler la partie du chemin des Izards qui est limitrophe de Toulouse et Launaguet, je cherche à identifier des doublons. En effet, ces tronçons limitrophes sont décrits deux fois dans le fichier, pour chaque commune qui gère son côté de voie.
CREATE OR REPLACE TABLE frontiere_izards AS
SELECT DISTINCT a.geometry,a.fromleft,a.fromright
FROM troncons_izards a
CROSS JOIN troncons_izards b
WHERE ST_Equals(a.geometry, b.geometry) AND a.code_insee <> b.code_insee
ORDER BY a.fromleft, a.fromright ;
Vérifions visuellement dans DBeaver : je retrouve bien la partie nord du chemin des Izards, celle qui sépare Toulouse et Launaguet :
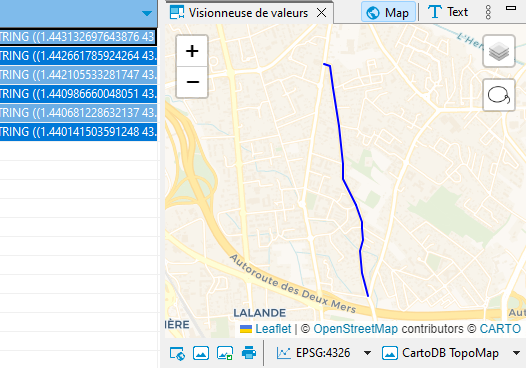
Ma deuxième entreprise consiste à élaborer un tampon de 100 mètres autour de cette voie.
Pour ce faire, je projette en coordonnées métriques avant de calculer le « buffer » :
CREATE OR REPLACE TABLE buffer_izards AS
SELECT ST_Union_Agg(geometry)
.ST_Transform('EPSG:4326','EPSG:2154',true)
.ST_Buffer(100) -- buffer de 100 mètres
.ST_Transform('EPSG:2154','EPSG:4326',true) AS geom,
quadkey_min_geo(geom) AS quadkey
FROM frontiere_izards ;
Vérifions l’allure de ce tampon, cela semble assez correct :
Indexation spatiale avec une quadkey
La dernière requête inclut le calcul d’une nouvelle information quadkey, qu’on appelle un index spatial. Ce quadkey suit le modèle de Microsoft avec Bing : la terre est découpée en une pyramide de quadrillages. On peut aller jusqu’au niveau 12 par exemple, et affecter à chaque petit carreau de ce niveau un code à 12 chiffres.
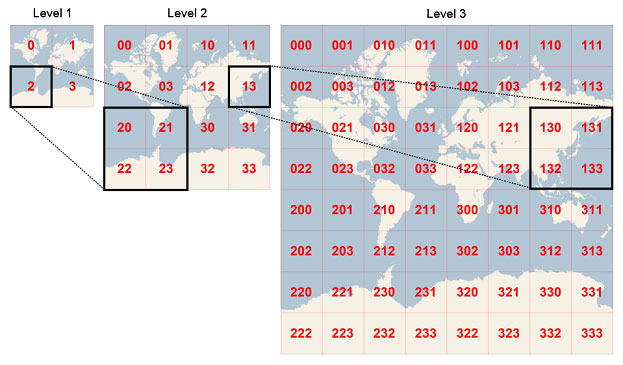
Ainsi, quand on travaille sur une zone géographique particulière, il est pratique de connaitre le quadkey du carreau qui l’englobe (à un niveau <=12). Cela servira à filtrer d’autres couches, comme la base d’adresses nationale que l’on va découvrir, si elle intègre elle aussi une colonne de quadkey.
La fonction ST_QuadKey() vient d’apparaitre dans la branche de dev de DuckDB spatial, elle sera disponible prochainement en version 0.9.3. Si vous voulez la tester, il suffit de l’installer de la façon suivante, dans le client DuckDB ou même dans la version web :
FORCE INSTALL spatial FROM 'http://nightly-extensions.duckdb.org' ;
ST_Quadkey() calcule le quadkey d’un point géométrique.
Le concepteur de l’extension DuckDB spatial prévoit même une fonction de calcul du quadkey du carreau le plus petit englobant une entité géographique quelconque (ligne, polygone).
Je la préfigure par cette macro :
CREATE OR REPLACE MACRO quadkey_min_geo(geom) AS (
WITH t1 AS (
SELECT
unnest(split(ST_Quadkey(ST_XMin(geom), ST_YMin(geom),12),'')) AS a,
unnest(split(ST_Quadkey(ST_XMin(geom), ST_YMax(geom),12),'')) AS b,
unnest(split(ST_Quadkey(ST_XMax(geom), ST_YMin(geom),12),'')) AS c,
unnest(split(ST_Quadkey(ST_XMax(geom), ST_YMax(geom),12),'')) AS d
)
SELECT string_agg(a,'') AS quadkey FROM t1 WHERE a = b AND b = c AND c = d
) ;
Ainsi, le quadkey calculé de notre tampon de 100 m autour du Chemin des Izards est :
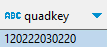
Examinons maintenant la base adresse nationale (BAN), je l’ai constituée au format GeoParquet à partir du csv.gz national, en l’enrichissant, pour chaque point adresse (et il y en a 26 millions), du quadkey correspondant. En voici un aperçu, sur un territoire mieux reconnaissable que la banlieue toulousaine :

Ainsi, la requête filtrée suivante ne charge que 6 Mo de données sur les 600 Mo du fichier parquet national – c’est tout l’intérêt de ce quadkey :
SELECT geom FROM 'https://static.data.gouv.fr/resources/ban-format-parquet/20250523-102223/adresses-france-10-2024.parquet'
WHERE quadkey LIKE '120222030220%' ;
Et je vais maintenant préciser ma demande avec un autre filtre spatial : que les adresses soient dans le « buffer Izards » :
SELECT a.geom FROM 'https://static.data.gouv.fr/resources/ban-format-parquet/20250523-102223/adresses-france-10-2024.parquet' a
JOIN buffer_izards b
ON ST_Within(a.geom, b.geom)
WHERE a.quadkey LIKE '120222030220%' ; -- 1 s
L’exécution ne prend ici qu’une seconde. C’est tout bonnement ahurissant.
Un opérateur de comparaison spatiale comme ST_Within() est coûteux, et s’il fallait le jouer sur les 26 millions d’adresses de la BAN, ce serait monstrueusement long. Restreindre le champ de cette comparaison aux seules adresses du carreau/quadkey pertinent nous fait gagner un temps fou.
Cela va vite aussi parce que j’ai recopié manuellement le quadkey du buffer. Une manière plus dynamique d’écrire cette requête serait :
SELECT a.geom FROM 'https://static.data.gouv.fr/resources/ban-format-parquet/20250523-102223/adresses-france-10-2024.parquet' a
JOIN buffer_izards b ON ST_Within(a.geom, b.geom)
WHERE a.quadkey LIKE (b.quadkey || '%') ; -- 4 s
Cette version prend désormais 4 secondes, ce qui reste peu, mais je trouve anormal qu’elle soit bien plus longue que la précédente. J’ai signalé ce cas concret à l’équipe DuckDB et ne doute pas qu’elle saura remettre la vélocité nécessaire ici ! (NDR 2025 : done !)
J’obtiens surtout 154 adresses de ménages qui auraient ainsi pu se mobiliser pour réclamer que la voie soit refaite.
Mais certains ont bien dû le faire, car la route a été aménagée à neuf depuis peu, agrémentée comme il se doit de moult chicanes et ralentisseurs…
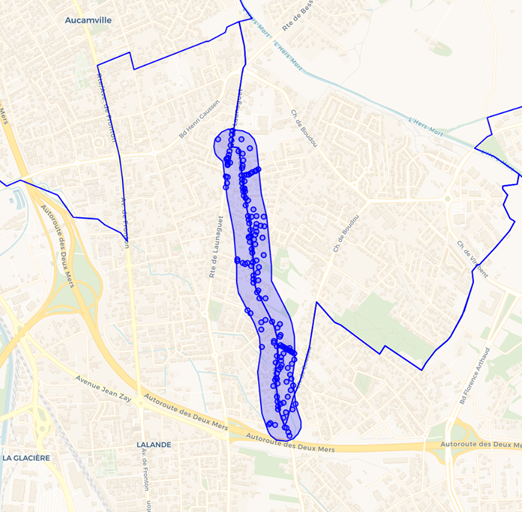
Pour visualiser ensemble ces adresses, le buffer, la portion limitrophe du chemin et les limites de Toulouse et Launaguet, tentons enfin de réunir ces différentes couches dans une seule table :
SELECT ST_union_agg(geometry) AS geom FROM frontiere_izards
UNION SELECT geom FROM buffer_izards
UNION (SELECT a.geom FROM 'https://static.data.gouv.fr/resources/ban-format-parquet/20250523-102223/adresses-france-10-2024.parquet' a
JOIN buffer_izards b ON ST_Within(a.geom, b.geom)
WHERE a.quadkey LIKE '120222030220%')
UNION SELECT ST_ExteriorRing(geom) FROM st_read('https://geo.api.gouv.fr/communes?code=31555&format=geojson&geometry=contour')
UNION SELECT ST_ExteriorRing(geom) FROM st_read('https://geo.api.gouv.fr/communes?code=31282&format=geojson&geometry=contour') ;
J’ai mobilisé au passage une API web, l’API Géo, pour récupérer le contour des deux communes. Ainsi, cette ultime requête mobilise ensemble des sources web indépendantes : la BAN (GeoParquet), le filaire de Toulouse métropole (GeoParquet), et l’API Géo (GeoJSON).
Et voici le résultat directement affiché dans DBeaver !
Le format GeoParquet
Ce format nait d’une initiative communautaire, désireuse d’utiliser Parquet pour encoder des fichiers géographiques. Parvenu en 2023 à sa version 1.0, GeoParquet est lu par le logiciel libre QGiS, qui permet donc de le visualiser, et supporté par des éditeurs majeurs (Esri, Carto, FME, Microsoft…)
Depuis août 2023, un groupe de travail au sein de l’OGC est chargé d’en affiner encore la spécification pour l’asseoir définitivement comme un standard géographique mondial. L’IGN anglais, l’Ordnance Survey, utilise déjà GeoParquet.
Un fichier GeoParquet est un fichier Parquet qui comprend des métadonnées géographiques spécifiques et encode la géométrie, officiellement au format WKB, mais aussi possiblement au format Arrow. Le format GeoArrow est donc un GeoParquet dans lequel la colonne de géométrie, au lieu du classique WKB, utilise une structure bien plus rapide à charger en mémoire, sans décodage.
D’une façon générale, le format GeoParquet est bien plus compact que ses alternatives. Comme tout fichier Parquet, on peut le lire (avec DuckDB par exemple) de façon sélective sur le web avec des « range requests », ce qui permet de requêter directement en https sans avoir à télécharger le fichier complet en local.
Il existe de multiples façons de convertir en GeoParquet un fichier géographique classique de type GeoJSON, shp, gpkg ou autres, par exemple :
- OGR/GDAL,
- librairies GeoPandas (Python), geoarrow (R),
- utilitaire gpq.
J’utilise plutôt ce dernier car, comme DuckDB, c’est un petit exécutable (30 Mo), sans dépendance. DuckDB ne sait pas – encore, mais ça va venir – exporter en GeoParquet. Mais il peut exporter un fichier géographique en Parquet standard, gpq venant ensuite le transformer en GeoParquet.
Ainsi, pour convertir la base adresse nationale (BAN) en GeoParquet, je commence dans DuckDB par un export Parquet :
COPY (
WITH ban AS (
SELECT *, ST_AsWKB(ST_point(lon, lat)) AS geometry,
ST_QuadKey(ST_point(lon, lat), 12) AS quadkey
FROM 'c:\...\adresses-france.csv.gz'
)
SELECT * EXCLUDE(lon,lat,x,y) FROM ban
ORDER BY quadkey
) TO 'c:\...\adresses-france.parquet' ;
Notez qu’une fois le champ de géométrie créé (obligatoirement en WKB), je n’ai plus besoin des colonnes redondantes lon, lat, x et y. Par ailleurs, je rajoute une colonne quadkey et, je trie sur cette colonne – très important – pour donner à cet indexation spatiale toute son efficacité.
Puis, en ligne de commande, je passe de Parquet à GeoParquet :
gpq convert c:\...\adresses-france.parquet c:\...\adresses-france-geo.parquet
--from=parquet --to=geoparquet --compression=zstd
Je peux aussi préciser un –row-group-length= pour ajuster la taille des row-groups dans le fichier, paramètre important pour accélérer les requêtes https : je dois avoir suffisamment de row-groups (une dizaine typiquement) pour que lire le ou les row-groups qui contiennent les données que je recherche soit efficace, fasse économiser beaucoup de bande passante.
adresses-france-geo.parquet est un peu plus léger (600 Mo) que le csv.gz téléchargeable (700 Mo). Et surtout, il est directement requêtable en https, avec une extraordinaire efficacité pour ses 26 millions d’adresses.
Conclusion de cette série de trois articles sur DuckDB et ses bluffantes potentialités
DuckDB, Parquet et GeoParquet nous font entrer dans un nouvel univers, qui dépasse le classique modèle client / « serveur spécialisé de base de données », ou client / API web.
À la place des boites noires sur serveur, qui implémentent en silo des API et des requêtes, le web entier devient une base de données généraliste, et c’est l’ordinateur de l’utilisateur qui fait le travail de requêtage, capable de charger sélectivement et sans enrobage inutile des flux de données brutes directement utilisables en mémoire.
Peu de personnes encore ont saisi toutes les implications de cette mutation. Voici quelques avantages très concrets :
- Économiser en gestion des données et d’accès concurrents sur les serveurs de mise à disposition : il suffit de déposer des fichiers et de laisser la magie du protocole https et des systèmes de cache opérer.
- Éviter à l’usager de télécharger des fichiers en local, de les dézipper, à chaque fois qu’il veut accéder aux données les plus fraiches.
- Dépasser la syntaxe obscure et variable des API web et surtout leurs limitations : formats de sortie verbeux, identification nécessaire parfois, limite en volume ou en nombre d’appels, lenteur souvent, pannes à l’occasion.
- Pouvoir dans la même requête interroger simultanément plusieurs sources de données sur le web, faire les jointures nécessaires à la volée.
- N’utiliser, côté utilisateur, que deux ou trois logiciels très simples, légers, rapides à charger, gratuits (le navigateur, év. un exécutable DuckDB indépendant si l’on utilise pas DuckDB dans le navigateur, DBeaver pour la productivité) et surtout un seul langage, le standard parmi les standards, SQL, flexible et intuitif.
- Accéder avec une vitesse incroyable à des fichiers plus volumineux, même avec une mémoire limitée.
Au-delà de la technique, j’ai voulu dans ces trois articles vous faire (re)découvrir la belle richesse des sources de données open data en France, en élaborant des cas d’usage les plus concrets et reproductibles possibles.
J’espère enfin que les gestionnaires de ces bases open data et des API liées sauront saisir les avantages, pour l’utilisateur, à proposer en complément de leur dispositif actuel des bases au format (geo)parquet.
Pour en savoir plus
- Meetup DuckDB Toulouse Dataviz, janvier 2024
- 3 explorations bluffantes avec DuckDB – Interroger des fichiers distants (1/3), icem7, 2023
- 3 explorations bluffantes avec DuckDB – Butiner des API JSON (2/3), icem7, 2023
- DuckDB – Spatial Extension
- DuckDB Spatial Extension – Documentation
- PostGEESE? Introducing The DuckDB Spatial Extension
- DuckDB: The indispensable geospatial tool you didn’t know you were missing – Chris Holmes, 2023
- Data Science is Getting Ducky, Paul Ramsey, 2023
- Two Tier Architectures are Anachronistic, Hannes Mühleisen, 2023
- Bing Maps Tile System
- GeoParquet – Github
- OGC forms new GeoParquet Standards Working Group, 2023
- Explorer la cartographie des réseaux de transports publics avec des données GTFS – Carto numérique, 2022
- Formation DuckDB, icem7
Si GeoParquet + DuckDB est indubitablement un élément de technologie efficace et qui peut sembler bluffant, il serait intéressant d’avoir également un article sur les limites de ces outils. Par exemples l’édition de la donnée, l’aspect multiuser/collaboratif, l’utilisation pour des référentiels de données, l’éventail de fonctions géospatiales disponibles, le support de types de données custom…
On a parfois tendance à sauter sur les nouveautés en pensant qu’un nouvel outil va répondre à tous les use cases et remplacer purement et simplement les outils précédents. Alors que la plupart du temps, le nouvel outil va répondre à un use case spécifique de façon très pertinente, mais sera rarement assez générique pour éclipser les autres. Le plus important est donc de bien connaitre les limites de chaque outil pour faire le bon choix lorsqu’on connait le use case cible.
DuckDB appartient à une famille d’outils analytiques (le A de OLAP) et c’est en tant qu’analyste, statisticien, que je m’y intéresse.
La saisie de la donnée, l’édition collaborative renvoie à d’autres technologies, transactionnelles, souvent plus traditionnelles. Les deux se complètent et DuckDB a le grand mérite d’ouvrir l’horizon analytique, en simplifiant considérablement l’accès et la manipulation des données, y compris géolocalisées, et le tout à moindre coût puisque c’est l’ordinateur de l’usager qui travaille.
Quelles conséquences sur l’industrie, les investissements pertinents quand on est responsable informatique, quel avenir pour les APIs JSON ? La rubrique « Pour en savoir plus » ci-dessus avance quelques réponses, mais forcément spéculatives à ce stade.