De plus en plus de bases sont désormais diffusées en parquet, ce format de données compact, maniable et spectaculairement rapide à interroger. Des outils simples le permettent.
J’observe pour autant ici ou là quelques défauts de préparation qui amoindrissent les avantages de ce nouveau format. Il est facile de les corriger avec un peu de vigilance, les bons outils, et le réflexe de tester ses fichiers avec quelques requêtes types.

7 points d'attention
1 – Des colonnes facilitant l’écriture d’une requête
Cela commence par des noms de colonnes simples à comprendre et à écrire dans une requête : en minuscules, sans accents ni blancs, d’une longueur modérée, par exemple inférieure à 15 caractères. Plutôt que « Code du département », on choisira par exemple « code_dept ».
À l’inverse, l’obscur « nb_vp » peut être précisé en « nb_veh_part » (pour nombre de véhicules particuliers).
On peut aussi ajouter des colonnes qui serviront souvent à filtrer le jeu de données. Pour des données quotidiennes renseignées avec un champ date, n’hésitons pas à placer un champ annee. En parquet, il ne prendra pas beaucoup de place, grâce à la compression.
2 – Définir les bons types de colonne
Une colonne de nombres codés en caractères n’est pas utilisable en l’état. La pire situation : des nombres avec virgule stockés comme du texte. De même, une date doit être décrite selon le type date : on pourra ainsi plus facilement la trier, en extraire le mois ou le jour de la semaine.
Je vois encore fréquemment des codes commençant par 0, comme un code département, qui perdent leur 0 : 09 devient 9, ou 04126 devient 4126. Voilà qui va compromettre les jointures avec d’autres fichiers bien construits.
Quelques optimisations plus fines amélioreront les performances : stocker un champ complexe (json, liste, hiérarchie) non comme du texte mais comme json, map ou struct. Un entier gagnera à être typé comme tel, et non comme float ou double ; un logique comme booléen et non « True » ou « False ».
3 – Trier le fichier selon une ou deux colonnes clés
Le tri est un critère essentiel : une requête filtrée sur un champ trié sera jusqu’à 10 fois plus rapide. Les requêtes de plage sur un fichier parquet permettent dans ce cas de cibler et réduire les seules plages à lire dans le fichier.
Par ailleurs, un fichier trié sur un ou deux champs de faible cardinalité (peu de valeurs distinctes) sera bien plus léger, bénéficiant d’une compression plus efficace.
Cas typiques : trier par année, puis code géographique ; trier un répertoire par code Siren ; trier un fichier géographique (geoparquet) par geohash.
4 – Choisir la meilleure stratégie de compression
Réduire la taille d’un fichier parquet n’est pas une fin en soi. Ce qui importe est de trouver le meilleur compromis entre gain de transfert et vitesse de décompression.
Le contexte d’usage doit aussi être pris en considération : le fichier parquet sera-t-il souvent accédé en ligne (auquel cas la bande passante et donc la compression des données transmises comptent), ou plutôt sur disque local rapide (et là on se passera volontiers du temps de décompression, et donc de la compression).
En pratique, la compression ZStd est la plus intéressante (davantage que le défaut Snappy) : elle est efficace et rapide à décoder.
5 – Ajouter une colonne bbox à un fichier geoparquet
Un fichier geoparquet décrit des données localisées qu’on voudra souvent filtrer à partir d’une emprise, typiquement un rectangle d’extraction. Chaque entité du geoparquet bénéficiera de la présence d’une colonne bbox (de type struct) définissant son rectangle englobant, conformément à la spécification geoparquet 1.1 en préparation.
La géométrie dans un géoparquet peut être codée en WKB ou en GeoArrow. Ce second format est bien plus performant et sera intégré à la spec geoparquet 1.1. Mais il faudra attendre encore un peu pour qu’il soit suffisamment adopté, notamment en lecture.
6 – Servir un fichier parquet à partir d’un stockage physique et non à la volée en API
Certaines plateformes proposent des formats parquet générés à la volée. Le processus est toujours affreusement lent (parquet est un format subtil et complexe à fabriquer). Et il compromet le requêtage direct en ligne car les métadonnées principales d’un parquet sont stockées à la fin du fichier. On perd donc la formidable possibilité propre à Parquet de réduire les plages de données à lire.
Parquet est un format de diffusion qui doit être stocké physiquement pour pouvoir être scanné rapidement (et bénéficier de la mise en cache des requêtes de plage).
7 – Affiner si besoin le nombre de row groups
Un fichier Parquet se structure en groupes de lignes (row groups), puis en colonnes. La taille de ces groupes de lignes doit être optimisée selon les usages pressentis : plutôt large si le fichier doit souvent être lu en grande part, plus réduite si les requêtes sont plutôt très sélectives (ce sera par exemple plus fréquent avec un fichier géographique).
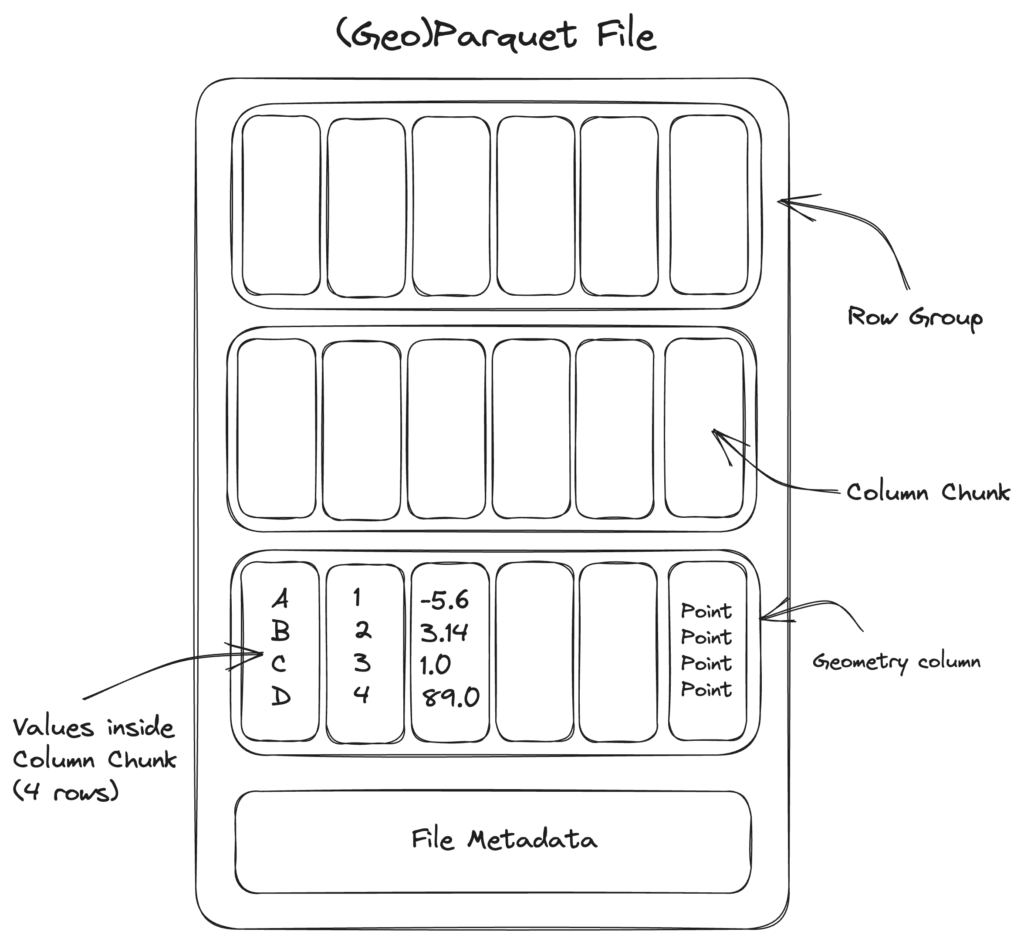
Rappels sur la structure d'un fichier parquet
Parquet est un format orienté colonne, mais il organise d’abord en groupes de lignes dans lesquels il dispose bout à bout les données des différentes colonnes. Ces « column chunks » ou morceaux de colonne sont compressibles et, comme chaque colonne présente un type homogène, cette compression est efficace.
Un fichier parquet est truffé de métadonnées : au niveau supérieur, décrivant la structure du fichier (nombre de lignes, liste des colonnes et leur type…) et au niveau de chaque row group : valeurs min et max de chaque column chunk, nombre de valeurs distinctes…
Un moteur de requête va prioritairement lire ces zones de métadonnées avant de décider quelles « plages de bits » extraire. Il lui est ainsi souvent possible de sauter plusieurs row groups dont il comprend qu’ils ne peuvent satisfaire la requête courante. Par ailleurs, seules les données des colonnes spécifiées dans la requête seront scannées. C’est tout l’intérêt d’un format orienté colonne.
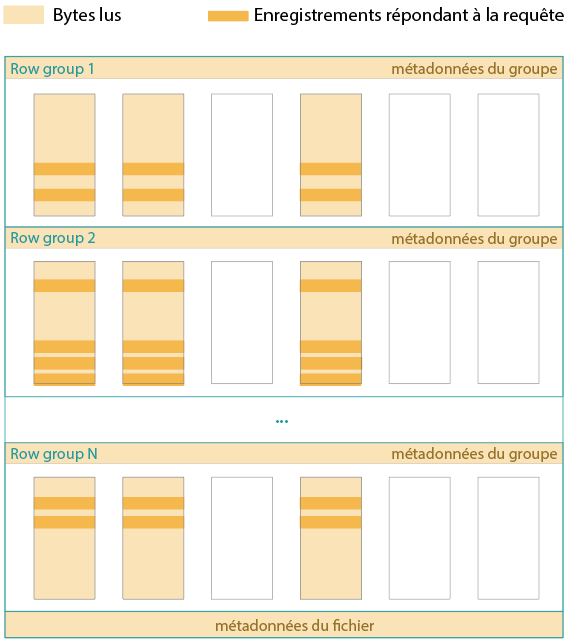
L'importance du tri
Prenons le cas d’un fichier non trié et d’une requête sélective, qui précise un critère de filtrage. Le schéma suivant matérialise en orange foncé les lignes à extraire des colonnes visées. Chaque row group en comprend, si bien qu’il va falloir extraire les données contenues dans tous les column chunks colorés.
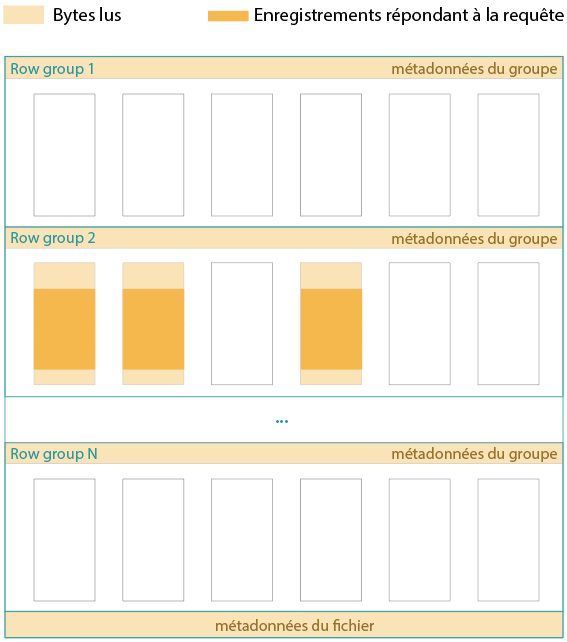
Quand le fichier est trié selon un ou deux champs clés, et que la requête filtre sur l’un de ces champs, notamment le premier, il y aura forcément un certain nombre de row groups « hors champ ». Par exemple, si j’extrais l’année 2018 d’un fichier comprenant des données quotidiennes entre 2010 et 2020, et que le fichier est d’abord trié par année.
Avec nettement moins de données à lire, la requête sera bien plus rapide. C’est ainsi que l’on peut requêter un fichier de 1 Go en ligne, en ne chargeant que quelques Mo de données.
Quels outils utiliser pour optimiser son Parquet ?
J’ai testé la conversion d’un fichier CSV de 5 Go et 25 millions de lignes (une base du recensement de l’Insee) en parquet, avec différents outils. Ce fichier est délimité par des ; et comprend entre autres une douzaine de codes pouvant commencer par 0.
DuckDB est l’outil plus maniable et le plus efficace : rapide, automatique, simple d’écriture.
Outil | Temps en minutes | Taille en Mo du parquet | Commentaires |
Polars/Rust | 1 | 500 | Spécifier délim et types des codes avec 0 en 1er |
DuckDB Cli threads 4 | 1 | 350 | Trop facile |
DuckDB Cli | 1,5 | 350 | Trop facile |
R/Arrow | 1,7 | 290 | Spécifier délim et types des codes avec 0 en 1er |
Python/Arrow | 2 | 290 | Spécifier délim et types des codes avec 0 en 1er |
R/Parquetize | 11 | 400 | CATL et TYPL mal typés (ex : 1.0 à la place de 1) |
Voici le meilleur compromis d’écriture avec DuckDB.
SET threads = 4 ;
COPY 'data_recensement_2017.csv' TO 'data_recensement_2017.parquet'
(compression zstd) ;
DuckDB reconnait tout seul le délimiteur français (;) et prend soin des colonnes avec des codes commençant parfois par 0. Enfin, l’outil DuckDB est super léger (25 Mo), s’installe et se lance en un clin d’œil.
Contrôler le nombre de threads, dans le cas de processus lourds, est souvent utile. Par défaut ce nombre équivaut au nombre de cœurs de la machine (12 dans mon cas, et réduire les threads du plan d’exécution à 4 accélèrera le traitement).
Polars dans Python est une bonne alternative (si vous utilisez déjà Python) pour une rapidité (équivalente). Mais Polars impose de spécifier le bon délimiteur et va maltraiter les colonnes de codes commençant par 0 si on ne le surveille pas de près.
Il faut donc lui préciser explicitement toutes les colonnes à préserver, c’est dissuasif et source d’erreurs. Enfin, le fichier généré est sensiblement plus gros. L’optimiser demanderait probablement à Polars plus de temps d’exécution.
import polars as pl
pl.read_csv("data_recensement_2017.csv", separator = ';', \
dtypes = {'COMMUNE': pl.String}) \
.write_parquet("data_recensement_2017.parquet", \
compression = 'zstd', use_pyarrow = False)
Dans R, la librairie arrow semble la plus véloce pour assurer la conversion de csv vers parquet, bien qu’un peu moins que Polars. Et comme lui, elle exige de préciser le délimiteur et le type des colonnes avec des 0.
library(arrow)
write_parquet(read_delim_arrow('data_recensement_2017.csv',
delim = ';', as_data_frame = FALSE), 'data_recensement_2017.parquet',
compression = 'zstd')
Autrement dit, si vous voulez travailler dans R ou Python, n’hésitez pas à utiliser la librairie DuckDB : c’est possible, plus simple à écrire, et plus rapide.
L'intérêt du partitionnement pour les très gros fichiers
Si votre fichier parquet doit dépasser les 10 Go et qu’il est plutôt utilisé en local ou sur un cloud comme S3 ou GCS, il y a tout intérêt à le découper en plusieurs fichiers selon les modalités d’un ou plusieurs champs clés, ce que l’on appelle partitionner.
L’instruction suivante crée ainsi une série de sous-répertoires dans lequel figure un fichier parquet par région. Mais on peut partitionner sur 2 colonnes ou plus.
COPY 'data_recensement_2017.csv'
TO 'export'
(FORMAT PARQUET, PARTITION_BY (REGION), compression zstd)
Dans cet exemple, si la requête ne concerne qu’une région, seul le fichier pertinent sera interrogé.
FROM read_parquet('export/*/*.parquet', hive_partitioning = true)
WHERE REGION = '76' ;
Quels outils utiliser pour optimiser son GeoParquet ?
Le cas geoparquet est particulier. DuckDB sait lire ce format, mais pas encore le générer (NDR : annoncé pour juillet 2024). Il faut donc pour l’heure en passer par exemple par Python (geopandas) ou R (sfarrow), à partir d’un format SIG classique (geojson, shape, gpkg, etc.).
Plus simple, si vous disposez de QGIS : exporter/sauvegarder sous au format geoparquet. De plus QGIS (profitant en cela de GDAL) permet de choisir l’encodage WKB ou GeoArrow. GDAL devrait permettre prochainement de produire une colonne bbox servant d’index spatial.
Enfin, pour accélérer plus encore les requêtes filtrées par emprise, ce sera une excellente idée que de trier votre Geoparquet astucieusement selon un indice de grille comme Geohash, H3, S2 ou une « quadkey ».
Un tel « hash » géographique peut être calculé par exemple à partir du centroide de chaque entité géographique. Deux hashes voisins (grâce au tri par exemple) garantissent que les entités correspondantes sont spatialement voisines.
La gigantesque base en ligne OvertureMaps est organisée de cette façon, et de surcroit partitionnée, si bien que cette requête DuckDB d’extraction de 500 m autour de la tour Eiffel ne lit que 13 Mo de données :
LOAD spatial ;
FROM read_parquet('s3://overturemaps-us-west-2/release/2024-05-16-beta.0/theme=places/type=*/*')
SELECT ST_GeomFromWKB(geometry) AS geom, names, categories
WHERE
bbox.xmin > 2.2877 AND
bbox.ymin > 48.8539 AND
bbox.xmax < 2.3013 AND
bbox.ymax < 48.8629 ;
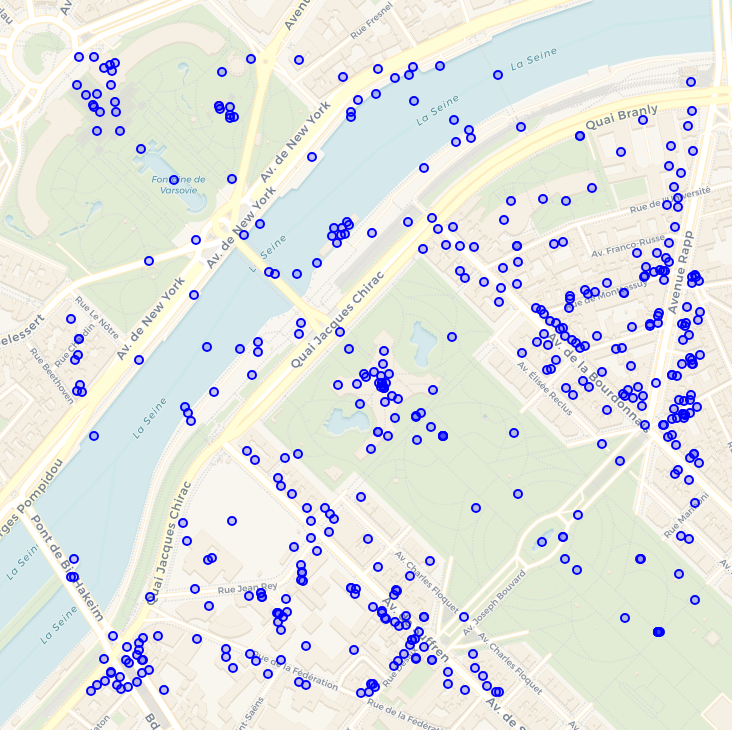
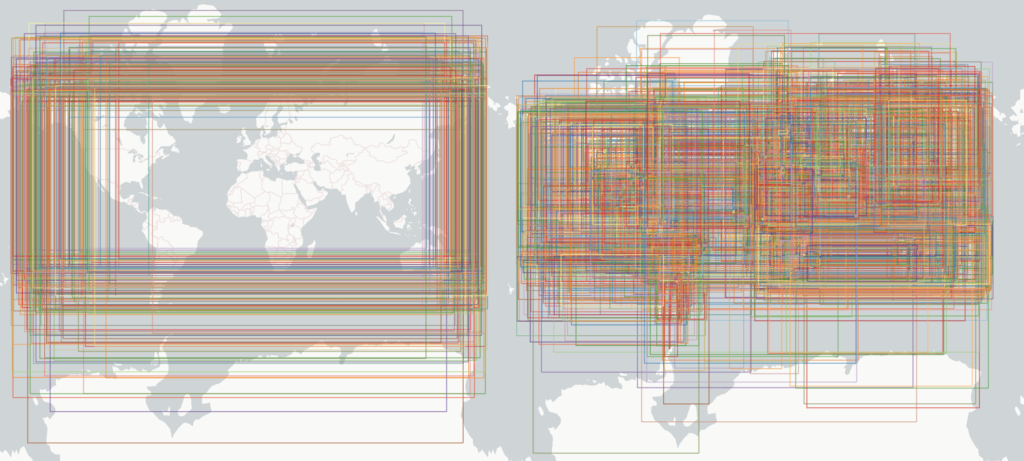
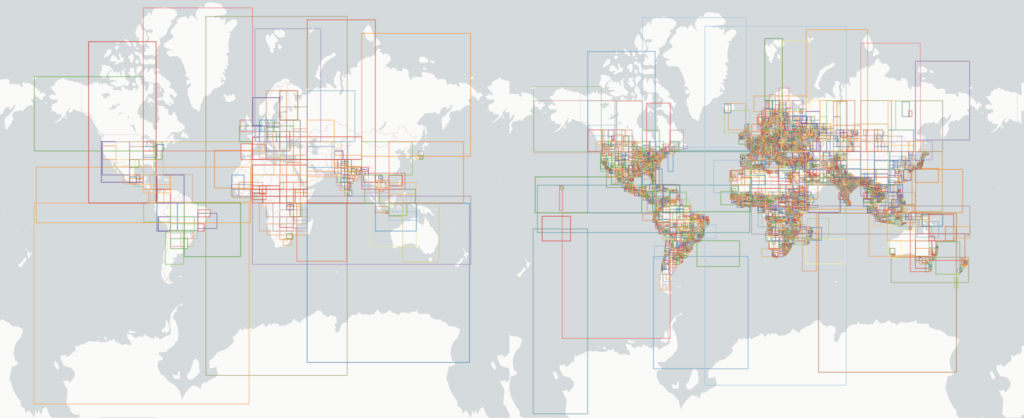
Jacob Wassemarman démontre par ces deux images la spectaculaire progression du partitionnement et du tri dans OvertureMaps.
Dans la version de janvier 2024, encore non optimisée, voici les rectangles englobants pour chaque fichier du partitionnement (à gauche) puis pour chaque row group (à droite) :
Depuis mars 2024, avec un partitionnement intelligent approchant les pays et un tri de chaque fichier par geohash, voici la différence, dont on comprend que l’impact sur l’efficacité des requêtes spatiales est radical :
Quelques instructions pour tester son fichier parquet
Un fichier parquet comprend de nombreuses métadonnées, qu’il est facile de lire dans DuckDB.
-- Métadonnées générales : nombre de lignes, nombre de row groups
FROM parquet_file_metadata('https://object.files.data.gouv.fr/data-pipeline-open/prod/elections/candidats_results.parquet');
-- Liste des colonnes avec leur type
FROM parquet_schema('https://object.files.data.gouv.fr/data-pipeline-open/prod/elections/candidats_results.parquet');
-- Liste des row groups, de leurs colonnes et statistiques pour chaque colonne (min, max, valeurs distinctes, valeurs nulles, compression...)
FROM parquet_metadata('https://object.files.data.gouv.fr/data-pipeline-open/prod/elections/candidats_results.parquet');
-- Métadonnées spécifiques, par exemple pour un geoparquet : bbox, type de géométrie, projection...
SELECT decode(key), decode(value)
FROM parquet_kv_metadata('s3://overturemaps-us-west-2/release/2024-05-16-beta.0/theme=places/type=*/*')
WHERE decode(KEY) = 'geo';
Pour connaitre le plan d’exécution et en particulier la bande passante utilisée par une requête, EXPLAIN ANALYZE est incontournable et nous aide à déterminer, à partir d’un choix de requêtes types les plus probables, les meilleurs options de tri, voire de taille des row groups.
EXPLAIN ANALYZE
FROM read_parquet('s3://overturemaps-us-west-2/release/2024-05-16-beta.0/theme=places/type=*/*')
SELECT ST_GeomFromWKB(geometry) AS geom, names, categories
WHERE
bbox.xmin > 2.2877 AND
bbox.ymin > 48.8539 AND
bbox.xmax < 2.3013 AND
bbox.ymax < 48.8629 ;
Pour en savoir plus
- DuckDB – Parquet tips
- GeoParquet 1.1 coming soon! – Chris Holmes
- An Empirical Evaluation of Columnar Storage Formats – Xinyu Zeng & al.
- The Battle of the Compressors: Optimizing Spark Workloads with ZStd, Snappy and More for Parquet
- Sorting and Parquet – Pankaj Gupta
- GeoParquet Spatial Sorting/Indexing/Partitioning – Jacob Wasserman
- Completely In-fused ! Guillaume Sueur
- Parquet devrait remplacer le format CSV – icem7
- 3 explorations bluffantes avec DuckDB – Interroger des fichiers distants (1/3), icem7
Super article ! Merci pour les tips